Multi-class classification (MCC) 是一個陳年題目,標準作法就是 softmax classification. Softmax MCC 在 CNN 分類網絡擔任 feature classification 最後收官角色。在 attention based 的 transformer, BERT 更是扮演主角。
另外在一些特殊的應用如人臉識別,不同的 softmax loss function 近年也有很多的進展。
值得更進一步探討背後的基本數學原理以及變形。最好有一個 unified theory vs. applications correspondence!
- Linear separable dataset, 特別是 binary dataset, SVM 的優勢 (i) maximum margin; (ii) efficiency computation for both training (convex optimization) and inference; (iii) intuitively explainable (supporting vectors). Logistic regression or softmax 完全沒有優勢,反而需要由 regulation 避免 overfit.
- Simple nonlinear separable dataset. kernel SVM has the advantage as above.
- Most linear/nonlinear separable but with some mixture data along the boundary. SVM or kernel SVM has the advantage
- 如果一定比例 data mixture 而且呈現一定 trend, 特別是 multi-class scenarios, probabilistic approach, logistic regression or softmax, 更有優勢。這在深度學習,transformer 可以看出。
本文結構:先 logistic regression for binary classification, link minimize cross-entropy loss to maximize log likelihood. 再來用 softmax function 重新推導 logistic regression and generalize to multi-class classification.
Softmax con: Too many parameters vs. convolution layer (WxH~1000×1000=1M parameters for CNN) and (? x? for transformer)
| Type | Softmax | SVM | IVM |
|---|---|---|---|
| Form | Exp(w.x)/sum(Exp()) | ||
| Probability | Yes | No | Yes |
| Rationale | Max. likelihood/similarity | Max. margin | ? |
| Loss function | Cross-entropy loss (above) | Hinge loss | ? |
| Application | CNN, transformer | classification | ? |
| Multiclass C inference | C(C-1)/2 binary | C probability | ? |
| Output, Y | 0 or 1 (binary) | +1 or -1 | 0 to 1?? |
| w,b training | w1-wc | supporting vectors | import vectors |
| Binary inference | exp comp. | linear compu. | ? exp comp? |
| Storage | NxM | support vector x N x M | ? exp comp? |
| Binary inference | boundary check | boundary check | ?import vectors |
| Multiclass C inference | C(C-1)/2 binary | C probability | ? |
| Differentiable | Yes | No | Yes |
Lots of new softmax!!
https://towardsdatascience.com/additive-margin-softmax-loss-am-softmax-912e11ce1c6b#:~:text=In%20short%2C%20Softmax%20Loss%20is,negative%20logarithm%20of%20the%20probabilities.
Loss function of LR and Softmax
[@houLogisticSoftmax2015]
Logistic Regression for Binary Classification
下圖是 binary classifier for N data points of D dimension with linear decision boundary (下圖 

Inference: Logistic Regression by Decision Boundary (Not Generalizable to Multi-Classes!)
基本想法是用 sigmoid function, 

![x_i, i=[1:N]](https://s0.wp.com/latex.php?latex=x_i%2C+i%3D%5B1%3AN%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
$latex y_i=\left\{\begin{array}{ll}
1 & 1 > h(x_i) > 0.5 \\
0 & 0 < h(x_i) < 0.5
\end{array}\right. $
where 
Decision boundary, 


Inference: Logistic Regression by Maximal Probability (Generalizable to Multi-Classes!)
只是把原來的想法稍微修改一下:
$latex y_i=\left\{\begin{array}{ll}
1 & h_1(x_i) > h_0(x_i) \\
0 & h_0(x_i) > h_1(x_i)
\end{array}\right. $
where 
此處只有最大或然率的觀念,沒有 decision boundary 的觀念。
在 binary classification 兩者等價,但背後的邏輯完全不同!下面會深入討論。

在 multi-class classification, 最大或然率分類簡單明瞭。
以 3-class 分類為例,對應的 output (e.g. one hot vector),
$latex y_i=\left\{\begin{array}{ll}
[1, 0, 0] & h_1(x_i) > h_2(x_i), h_3(x_i) \\
[0, 1, 0] & h_2(x_i) > h_1(x_i), h_3(x_i) \\
[0, 0, 1] & h_3(x_i) > h_1(x_i), h_2(x_i)
\end{array}\right. $
where 


Training/Learning: 如何得到 w and b
所有 machine learning 的 training 都是先 formulate 成一個 loss function of minimum value, i.e. 

Maximum Likelihood for Probabilistic Interpretation ML
Minimum loss 和 maximum likelihood method 非常相似!
我們先複習一下 maximum likelihood, 再連結 minimum loss.
Let 



簡單的例子:n 個 coins with k heads and n-k tails.




Logistic Regression's Maximum Likelihood Interpretation [@roelantsSoftmaxClassification2019]
對於具有 probabilistic interpretation 的 ML problem, 是否可以用 maximum likelihood approach 求解 parameter? Yes, of course!
以 logistic regression 為例,假設有一個 underlying probability distribution based on parameter. Let 


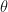




因為 


![y_i \in [0, 1]](https://s0.wp.com/latex.php?latex=y_i+%5Cin+%5B0%2C+1%5D+&bg=ffffff&fg=111111&s=0&c=20201002)

實務上不會只用單點決定 parameter. 假設 n data points 彼此互相獨立。The likelihood function,

一般的 Maximum Likelihood: 
但更常用 Minimum -log likelihood, 
因為 log function 是 monotonic function. 此處 


where

Logistic Regression Cross-Entropy Loss
一般 Logistic Regression (LR) or softmax 的 cross-entropy loss function [@brownleeGentleIntroduction2019],

比較之下,其實 cross-entropy loss 就是 -log(likelihood). Minimize cross-entropy loss = Maximize log likelihood = Maximize likelihood!
對於熟悉 entropy 觀念的人,可能會覺得 entropy or cross-entropy 更直觀或基本。對我而言,把 cross-entropy loss 連結到 negative log likelihood 容易理解。
上式可以推廣到 loss function and multi-class classification.
Generalize to Multi-class Classification Using Softmax [@houLogisticSoftmax2015]
如何把 binary classification 的 logistic regression 推廣到 multi-class classification? 我們用 softmax 重新推導 binary classification (等價 logistic regression) 以及定義其 loss function. 下一步再推廣到 multi-class classification.
Softmax Function
什麼是 softmax? 我們先看什麼是 hard maximum. Hardmax 是 indictor vector of the original vector's maximum position, 對應 maximum 的 value 為 1, 其餘為 0.
舉個例子 A = [2, 4, 6, 1, 7], hardmax(A) = [0, 0, 0, 0, 1].
Hardmax 有幾個缺點:
- 如果有兩個或是多個 maximum, 結果不唯一。例如 A = [2, 4, 6, 6], hardmax(A) = [0, 0, 0, 1] or [0, 0, 1, 0].
- 大部分的資訊都流失,從 hardmax(A) 無法回溯 (back inject) 原始的資訊,除了 maximum 的 position.
- Not differentiable, 無法 back propagate.
因此 Softmax 就應運而生:
-
Step 1 是把 A 所有 value 都 raise to exponents. Step 2 再 normalize to sum to 1.
-
A = [2, 4, 6, 1, 7], softmax(A) = [0.005, 0.035, 0.258, 0.002, 0.7]. 最大的 "7" 佔 70%, “6” 佔 26%, 其他值加起來不到 5%. 基本上所有的資訊都被 compressed 到 0 到 1 之間值,可以視為機率,同時 differentiable.
-
Softmax 的 probability 特性剛好 match maximum log likelihood = minimize cross-entropy loss.

Binary Classification
假設如下的 binary labelled dataset (
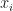



如何有最大的相似性?最簡單的相似性就是用 inner product, 


![= \max_{w_0, w_1} \sum_i [(1-y_i) (w_0 \cdot x_{i}) + y_i (w_1 \cdot x_{i}) ]](https://s0.wp.com/latex.php?latex=%3D+%5Cmax_%7Bw_0%2C+w_1%7D+%5Csum_i+%5B%281-y_i%29++%28w_0+%5Ccdot+x_%7Bi%7D%29+%2B+y_i++%28w_1+%5Ccdot+x_%7Bi%7D%29+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)


上式的問題是 inner product 可以是正或負,正負會互相抵銷。可以改良用 exp 變成都是正值,再 normalize the sum to 1, 避免爆掉。這正是 softmax function 所有的值介於 0 to 1, 用來取代原來的相似性 inner product!
![\max_{w_0, w_1} \sum_i [(1-y_i)\frac{e^{ w_0\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}}} + y_i \frac{e^{ w_1\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}}} ]](https://s0.wp.com/latex.php?latex=%5Cmax_%7Bw_0%2C+w_1%7D+%5Csum_i+%5B%281-y_i%29%5Cfrac%7Be%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D+%2B+y_i+%5Cfrac%7Be%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
![= \max_{w_0, w_1} \sum_i [(1-y_i) P(y_i=0 \mid x_i, w_0) + y_i P(y_i=1 \mid x_i, w_1) ]](https://s0.wp.com/latex.php?latex=%3D+%5Cmax_%7Bw_0%2C+w_1%7D+%5Csum_i+%5B%281-y_i%29+P%28y_i%3D0+%5Cmid+x_i%2C+w_0%29+%2B+y_i+P%28y_i%3D1+%5Cmid+x_i%2C+w_1%29+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
進一步改良,因為 softmax output 可以視為 probability. 可以用 log probability, i.e. -log P (natural log) 轉為 entropy. 因為乘以 (-1), maximum similarity 轉為 minimum (cross) entropy loss. 為什麼要用 entropy 取代 probability? 一方面是 entropy 更有“物理”意義, e.g. minimum cross-entropy loss, maximum entropy principle, maximum energy principle. 另一方面 cross-entropy loss punish small probability, 

![\min_{w_0, w_1} \sum_i [-(1-y_i)\log \frac{e^{ w_0\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}}} - y_i \log \frac{e^{ w_1\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}}} ]](https://s0.wp.com/latex.php?latex=%5Cmin_%7Bw_0%2C+w_1%7D+%5Csum_i+%5B-%281-y_i%29%5Clog+%5Cfrac%7Be%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D+-+y_i+%5Clog+%5Cfrac%7Be%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
在 binary classification 的 special case, 
Sanity check: 



相反 




In summary, maximum similarity 
上式的 ![\min_{w} \sum_i [-(1-y_i)\log \frac{1}{ 1 + e^{ +w\cdot x_{i}}} - y_i \log \frac{1}{1 + e^{ -w\cdot x_{i}}} ]](https://s0.wp.com/latex.php?latex=%5Cmin_%7Bw%7D+%5Csum_i+%5B-%281-y_i%29%5Clog+%5Cfrac%7B1%7D%7B+1+%2B+e%5E%7B+%2Bw%5Ccdot+x_%7Bi%7D%7D%7D+-+y_i+%5Clog+%5Cfrac%7B1%7D%7B1+%2B+e%5E%7B+-w%5Ccdot+x_%7Bi%7D%7D%7D+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
![= \min_{w} \sum_i [-(1-y_i)\log (1-h(x_i)) - y_i \log h(x_i) ]](https://s0.wp.com/latex.php?latex=%3D+%5Cmin_%7Bw%7D+%5Csum_i+%5B-%281-y_i%29%5Clog+%281-h%28x_i%29%29+-+y_i+%5Clog+h%28x_i%29+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)

![\min_{w} \sum_i [-(1-y_i)\log \frac{1}{ 1 + e^{ +w\cdot x_{i}+b}} - y_i \log \frac{1}{1 + e^{ -w\cdot x_{i}-b}} ]](https://s0.wp.com/latex.php?latex=%5Cmin_%7Bw%7D+%5Csum_i+%5B-%281-y_i%29%5Clog+%5Cfrac%7B1%7D%7B+1+%2B+e%5E%7B+%2Bw%5Ccdot+x_%7Bi%7D%2Bb%7D%7D+-+y_i+%5Clog+%5Cfrac%7B1%7D%7B1+%2B+e%5E%7B+-w%5Ccdot+x_%7Bi%7D-b%7D%7D+%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
另一個重點是 regularization, 上式的 

以下圖 1D logistic regression 為例,w 對應 transition region 的斜率:假設 y=0 (下圖 'o') 和 y=1 (下圖 'x') 是 totally separable, 紅線 (w=2) 和藍線 (w=1) 都可以很好的 fit data, 但是 w=2 的 cross-entropy loss 比較小。如果沒有 regularization, w 愈大 (e.g. 
![\min_{w} \sum_i \left[-(1-y_i)\log \frac{1}{ 1 + e^{ +w\cdot x_{i}+b}} - y_i \log \frac{1}{1 + e^{ -w\cdot x_{i}-b}} \right] + \lambda \| w\|^2](https://s0.wp.com/latex.php?latex=%5Cmin_%7Bw%7D+%5Csum_i+%5Cleft%5B-%281-y_i%29%5Clog+%5Cfrac%7B1%7D%7B+1+%2B+e%5E%7B+%2Bw%5Ccdot+x_%7Bi%7D%2Bb%7D%7D+-+y_i+%5Clog+%5Cfrac%7B1%7D%7B1+%2B+e%5E%7B+-w%5Ccdot+x_%7Bi%7D-b%7D%7D+%5Cright%5D+%2B+%5Clambda+%5C%7C+w%5C%7C%5E2++&bg=ffffff&fg=111111&s=0&c=20201002)
或者 cross-entropy loss 先平均 w.r.t. N data points, 再加上 regularization:
![\min_{w} \frac{1}{N}\sum_i \left[-(1-y_i)\log \frac{1}{ 1 + e^{ +w\cdot x_{i}+b}} - y_i \log \frac{1}{1 + e^{ -w\cdot x_{i}-b}} \right] + \lambda \| w\|^2](https://s0.wp.com/latex.php?latex=%5Cmin_%7Bw%7D+%5Cfrac%7B1%7D%7BN%7D%5Csum_i+%5Cleft%5B-%281-y_i%29%5Clog+%5Cfrac%7B1%7D%7B+1+%2B+e%5E%7B+%2Bw%5Ccdot+x_%7Bi%7D%2Bb%7D%7D+-+y_i+%5Clog+%5Cfrac%7B1%7D%7B1+%2B+e%5E%7B+-w%5Ccdot+x_%7Bi%7D-b%7D%7D+%5Cright%5D+%2B+%5Clambda+%5C%7C+w%5C%7C%5E2++&bg=ffffff&fg=111111&s=0&c=20201002)

一般 data y=0 和 y=1 非 totally separable, cross-entropy loss 會限制 w 的 optimal range.
Multi-Class Classification
從 binary classification 推廣到 multi-class classification 很直接。下式是 3-class loss function:
![\sum_i \left[-y^0_i\log \frac{e^{ w_0\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}} + e^{ w_2\cdot x_{i}}} - y^1_i \log \frac{e^{ w_1\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}} + e^{ w_2\cdot x_{i}}} - y^2_i \log \frac{e^{ w_2\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}} + e^{ w_2\cdot x_{i}}}\right]](https://s0.wp.com/latex.php?latex=%5Csum_i+%5Cleft%5B-y%5E0_i%5Clog+%5Cfrac%7Be%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_2%5Ccdot+x_%7Bi%7D%7D%7D+-+y%5E1_i+%5Clog+%5Cfrac%7Be%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D++%2B+e%5E%7B+w_2%5Ccdot+x_%7Bi%7D%7D%7D+-+y%5E2_i+%5Clog+%5Cfrac%7Be%5E%7B+w_2%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_2%5Ccdot+x_%7Bi%7D%7D%7D%5Cright%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
where ![[y^0_i, y^1_i, y^2_{i}]](https://s0.wp.com/latex.php?latex=%5By%5E0_i%2C+y%5E1_i%2C+y%5E2_%7Bi%7D%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
再來推廣到 C classes using the notation of [@roelantsSoftmaxClassification2019].
![\sum_i \sum_{c=1}^C \left[-y^c_i\log \frac{e^{ w_c\cdot x_{i}}}{ e^{ w_0\cdot x_{i}} + e^{ w_1\cdot x_{i}} + ... + e^{ w_C\cdot x_{i}}} \right]](https://s0.wp.com/latex.php?latex=%5Csum_i+%5Csum_%7Bc%3D1%7D%5EC+%5Cleft%5B-y%5Ec_i%5Clog+%5Cfrac%7Be%5E%7B+w_c%5Ccdot+x_%7Bi%7D%7D%7D%7B+e%5E%7B+w_0%5Ccdot+x_%7Bi%7D%7D+%2B+e%5E%7B+w_1%5Ccdot+x_%7Bi%7D%7D+%2B+...+%2B+e%5E%7B+w_C%5Ccdot+x_%7Bi%7D%7D%7D+%5Cright%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
因為 


上式平均 w.r.t N data points, 再加上 regularization, softmax multi-class classification formulation 如下式。常用於深度學習的 feature classification, transformer 的 attention network.

Likelihood to Cross-Entropy Function
幾個重點:
- Softmax classification 的邏輯是 maximum similarity between
and
(等價 maximum (log) likelihood = 等價 minimum entropy loss)! 再加上 regularization. Maximum similarity 的邏輯很容易推廣到 multi-class classification!
-
SVM 是找 maximum margin decision boundary (等價 regularization) 再加上 minimize hinge loss. SVM 似乎比較適合 binary classification where the decision boundary is easier to defined and understood. 如果是 multi-class classification, 就要變成多個 binary classification.
-
let
and
-
Normalize the sum:
and
.
and
是
and
的 softmax.
-
where
-
當然,
-
加上一個 bias,
不會改變以上結論,就得出 logistic regression. 但在 softmax 還可以有這個 bias 嗎?
-
If
此處用到 exp and log 都是 monotonic functions. 但如何定義 loss function?
and
-
什麼是 loss function? 就是 given
, 如果你選
, 而 P(y_1 | x) = 1 代表選對了,loss = 0; 如果 P(y_1 | x) = 0.01,代表選錯了, loss 等於 big positive number. 神奇的 function 就是用
, 。 : make wrong decision -(y = 1) x log( h_0(x))
-
Use probability
-
And the loss function is log P().
以上 Logistic Regression (LR) 的 loss function:





Log Base:  or
or  or
or  ?
?
Logistic regression and softmax loss function, use natural log = ln 因為 exp().
Classification cross-entropy loss function, use log_2 因為可以用 bits.
Continuous loss function, use log 單位是 neper?
基本上沒有 log_10 in ML?
Cross-entropy can be calculated using the probabilities of the events from P and Q, as follows:
H(P, Q) = – sum x in X P(x) * log(Q(x))
Where P(x) is the probability of the event x in P, Q(x) is the probability of event x in Q and log is the base-2 logarithm, meaning that the results are in bits. If the base-e or natural logarithm is used instead, the result will have the units called nats.
!!!! softmax 的精神是找出 w vector 和 data 的相似性,而不是 decision boundary. 所以可以推廣到 multi-class classification!!!
!!! SVM 是找出 decision boundary. 對於 binary OK, but multi-class classification 就很 akward.
設如下的 binary labelled dataset (
