Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.
Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.
我寫 blog 目的是把自己讀過或做過的工程,物理,資訊,語言做一些紀錄,間或做一些整理便於之後快速查詢。最近 (2021) 看到蘇劍林似乎很早就在經營科學空間 https://spaces.ac.cn 做的非常好。其中一些文章對我很有幫助。
我也想把之前或之後的紀錄和心得能夠更好的呈現,主要還是為了自己的整理和查詢。當然如果能有助於他人更好。因此找到一個適合呈現 math equation, figure, 並且可以長時間存在的 blog 平台就很重要。
Blogger (Google) 和 WordPress (Open) 對於 math equation 很多問題。 Medium 我沒試過,但我不喜歡付費才能閱讀。最近 (2020) 試了一下 Jekyll (markdown to html) + Next theme + Github.io (Blog platform, now Microsoft) 似乎是不錯的組合。產生的 math equation 最接近我想要的呈現。因此我會把一些文章逐步搬到 Github.io: https://allenlu2009.github.io 特此為誌。
Maximum likelihood estimation (MLE) 最大概似估計是一種估計模型參數的方法。適用時機在於手邊有模型,但是模型參數有無限多種,透過真實觀察到的樣本資訊,想辦法導出最有可能產生這些樣本結果的模型參數,也就是挑選使其概似性(Likelihood)最高的一組模型參數,這系列找參數的過程稱為最大概似估計法。
Bernoulli distribution:投擲硬幣正面的機率 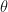

MLE 在無限個
只要 likelihood function 一次微分,可以得到
就是平均值,推導出來的模型參數符合直覺。
Normal distribution: 假設 mean unknown, variance known, 我們可以用 maximum log-likelihood function
$latex \begin{aligned}
&\frac{\mathrm{d}}{d \mu}\left(\sum_{i=1}^{n}-\frac{\left(x_{i}-\mu\right)^{2}}{2 \sigma^{2}}\right)=\sum_{\mathrm{i}=1}^{\mathrm{n}} \frac{\left(x_{i}-\hat{\mu}\right)}{\sigma^{2}}=\sum_{i=1}^{n} x_{i}-n \hat{\mathrm{u}}=0 \\
&\hat{\mu}=\overline{\mathrm{X}}=\frac{\sum_{i=1}^{n} x_{i}}{n}
\end{aligned} $
微分的結果告訴我們,樣本的平均值,其實就是母體平均值 
這是一個錯覺,常見的 distribution (e.g. Bernoulli, normal distribution) 都是 exponential families. 可以證明 maximum log-likelihood functions of exponential families 都是 concave function, 沒有 local minimum. 非常容易用數值方法找到最佳解,而且大多有 analytical solution.
但只要 distribution function 更複雜一點,例如兩個 normal distribution weighted sum to 1, MLE 就非常難解。這是 EM algorithm 為什麼非常有用。
一個簡單例子觀察 temperature and amount of snow (溫度和雪量, both are binary input) 的 joint probability depending on two "scalar factors" 


 |
 |
|
|---|---|---|
 |
|
 |
 |
 |
|
注意
另外因為機率和為 1 做為一個 constraint:
一個 ski-center 觀察 

|
|
|
|---|---|---|
|
 |
 |
|
 |
 |
Likelihood function (就是 joint pdf of
where 
問題改成 maximum log-likelihood with constraint and
$latex \begin{gathered}
\frac{\partial L}{\partial a}=N_{00} \frac{1}{a}+N_{01} \frac{1}{a}+6 \lambda=0 \\
\frac{\partial L}{\partial b}=N_{10} \frac{1}{b}+N_{11} \frac{1}{b}+4 \lambda=0 \\
\frac{\partial L}{\partial \lambda}=6 a+4 b – 1 = 0
\end{gathered} $
上述方程式的解為
結果很直觀。其實就是利用大數法則:
再來大數法則 (a+5a)N~N00+N01; (3b+b)N~N10+N11 => a = .. ; b = …
假設我們無法觀察到完整的"溫度和雪量“;而是“溫度或雪量”,有時“溫度”,有時“雪量”,但不是同時。對應的不是 joint pdf, 而是 marginal pdf 如下:

觀察如下:

The Lagrangian (log-likelihood with constraint)
此時的方程式比起之前複雜的多,不一定有 close-form solution:
$latex \begin{gathered}
\frac{\partial L}{\partial a}=\frac{T_{0}}{a}+\frac{S_{0}}{a+3 b}+\frac{5 S_{1}}{5 a+b}+6 \lambda=0 \\
\frac{\partial L}{\partial b}=\frac{T_{1}}{b}+\frac{3 S_{0}}{a+3 b}+\frac{S_{1}}{5 a+b}+4 \lambda=0 \\
6 a+4 b=1
\end{gathered} $
如果用大數法則:


 constraint, 可以用來估計 and .
constraint, 可以用來估計 and . ? 單獨用一組都會損失一些 information, 應該要 combine 1 and 2 的 information, how?
? 單獨用一組都會損失一些 information, 應該要 combine 1 and 2 的 information, how?思路一 平均 (a, b) from 1 and 2. 但這不是好的策略,因為平均 (a,b) 不一定滿足 constraint. 在這個 case 因為 linear constraint, 所以平均 (a,b) 仍然滿足 constraint. 但對於更複雜 constraint, 平均並非好的方法。
更重要的是平均並無法代表 maximum likelihood in the above equation. 我們的目標是 maximum likelihood, 平均 (a, b) 完全無法保證會得到更好的 likelihood value!
或者把 (a,b) from 1 or 2 代入上述 likelihood function 取大值。顯然這也不是最好的策略。因為一半的資訊被捨棄了。
思路二 比較好的方法是想辦法用迭代法解微分後的 Lagrange multiplier 聯立方程式。 (a, b) from 1. or 2. 只作為 initial solution, 想辦法從聯立方程式找出 iterative formula. 這似乎是對的方向,問題是 Lagrange multiplier optimization 是解聯立(level 1)微分方程式。不一定有 close form as in this example. 同時也無法保證收斂。另外如何找出 iterative formula 似乎是 case-by-case, 沒有一致的方式。
=> iterative solution is one of the key, but NOT on Lagrange multiplier (level 1)
思路三 既然是 missing data, 我們是否可以假設 


有了 
Q: 如何證明這個方法是最佳或是對應 complete data MLE or incomplete/hidden data MLE? 甚至會收斂?
We measure lengths of vehicles. The observation space is two-dimensional, with 



where

Log-likelihood
很容易用 MLE 估計
直觀上很容易理解。如果 observations 已經分組,求 mean 只要做 sample 的平均即可。
以這個例子,ratio 
$latex \mathcal{T}=\{\left(\operatorname{car}, y_{1}^{(c)}\right), \ldots,\left(\operatorname{car}, y_{C}^{(c)}\right),\left(\text {truck}, y_{1}^{(\mathrm{t})}\right), \ldots,\left(\text {truck}, y_{T}^{(\mathrm{t})}\right), \underbrace{\left(\bullet, y_{1}^{\bullet}\right), \ldots,\left(\bullet, y_{M}^{\bullet}\right)}_{\begin{array}{l}
\text { data with uknown } \\
\text { vehicle type }
\end{array}}\} $
Log-likelihood
$latex \ell(\mathcal{T})=\sum_{i=1}^{N} \ln p\left(x_{i}, y_{i} \mid \mu_{c}, \mu_{\mathrm{t}}\right)=\overbrace{C \ln \kappa_{\mathrm{c}}-\frac{1}{2} \sum_{i=1}^{C}\left(y_{i}^{(c)}-\mu_{\mathrm{c}}\right)^{2}+T \ln \kappa_{\mathrm{t}}-\frac{1}{8} \sum_{i=1}^{T}\left(y_{i}^{(\mathrm{t})}-\mu_{\mathrm{t}}\right)^{2}}^{\text {same term as before }} \\
+\sum_{i=1}^{M} \ln \left(\kappa_{\mathrm{c}} \exp \left\{-\frac{1}{2}\left(y_{i}^{\bullet}-\mu_{\mathrm{c}}\right)^{2}\right\}+\kappa_{\mathrm{t}} \exp \left\{-\frac{1}{8}\left(y_{i}^{\bullet}-\mu_{\mathrm{t}}\right)^{2}\right\}\right) $
不用微分也知道非常難解 MLE. 我們必須用另外的方法,就是 EM 算法。
不過我們還是微分一下,得到更多的 insights.
$latex \begin{aligned}
0=\frac{\partial \ell(\mathcal{T})}{\partial \mu_{\mathrm{c}}} &=\sum_{i=1}^{C}\left(y_{\mathrm{c}}^{(\mathrm{c})}-\mu_{\mathrm{c}}\right) \\
&+ \sum_{i=1}^{M} \overbrace{\frac{\kappa_{\mathrm{c}} \exp \left\{-\frac{1}{2}\left(y_{i}^{\bullet}-\mu_{\mathrm{c}}\right)^{2}\right\}}{\kappa_{\mathrm{c}} \exp \left\{-\frac{1}{2}\left(y_{i}^{\bullet}-\mu_{\mathrm{c}}\right)^{2}\right\}+\kappa_{\mathrm{t}} \exp \left\{-\frac{1}{8}\left(y_{i}^{\bullet}-\mu_{\mathrm{t}}\right)^{2}\right\}}}^{p\left(\operatorname{car} \mid y_{i}^{\bullet}, \mu_{\mathrm{c}}, \mu_{\mathrm{t}}\right)}\left(y_{i}^{\bullet}-\mu_{\mathrm{c}}\right)
\end{aligned} $
上兩式非常有物理意義。基本是 easy case 的延伸:已知分類的平均值,加上未知分類的機率平均值。一個簡單的方法是只取前面已知的部分平均,不過這不是最佳,因為丟失部分的資訊。
重新 summarize optimality conditions
如果 



EM algorithm 剛好用來打破這個迴圈。
 denote the missing data. Define
denote the missing data. Define 
EM Algorithm 可以用以下四步驟表示
, for  , according to the above equations.
, according to the above equations.上述步驟 2 稱為 Expectation (E) Step, 步驟 3 稱為 Maximization (M) Step. 統稱為 EM algorithm.
Q. Why Step 2 稱為 Expectation? not clear. Maximization 比較容易理解,因為 optimality condition 就是 maximization (微分為 0).
In summary, EM algorithm 的一個關鍵點是:讓 incomplete/hidden data 變成 complete (Expectation?). 有了完整的 data, 就容易用 MLE 找到 maximal likelihood estimation (

EM algorithm 如果只是 heuristic algorithm, 可能有用度減半。這裡討論數學上的 justification. 先定義 terminologies
 : all observed values
: all observed values : all unobserved values (i.e. hidden variable)
: all unobserved values (i.e. hidden variable) : model parameters to be estimated
: model parameters to be estimated目標:Find 
思路:假設解下列完整 data 很容易解 (例如上面的 exmple xx and xx)
我們的想法是把上上式改寫成上式,再加以優化
$latex \begin{aligned}
\ln p(\mathbf{o} \mid \boldsymbol{\theta}) &=\ln \sum_{\mathbf{z}} p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta}) \\
&=\ln \sum_{\mathbf{z}} q(\mathbf{z}) \frac{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}{q(\mathbf{z})}
\end{aligned} $
這裡引入 

我們定義 


這已經非常接近思路!
Maximizing 
反過來我們可以計算和 lower bound 之間的 gap.
$latex \begin{aligned}
\ln p(\mathbf{o} \mid \boldsymbol{\theta})-\mathcal{L}(q, \boldsymbol{\theta}) &=\ln p(\mathbf{o} \mid \boldsymbol{\theta})-\sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}{q(\mathbf{z})} \\
&=\ln p(\mathbf{o} \mid \boldsymbol{\theta})-\sum_{\mathbf{z}} q(\mathbf{z})\{\ln \underbrace{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}_{p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) p(\mathbf{o} \mid \boldsymbol{\theta})}-\ln q(\mathbf{z})\} \\
&=\ln p(\mathbf{o} \mid \boldsymbol{\theta})-\sum_{\mathbf{z}} q(\mathbf{z})\{\ln p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta})+\ln p(\mathbf{o} \mid \boldsymbol{\theta})-\ln q(\mathbf{z})\} \\
&=\ln p(\mathbf{o} \mid \boldsymbol{\theta})-\underbrace{\sum_{\mathbf{z}} q(\mathbf{z})}_{1} \ln p(\mathbf{o} \mid \boldsymbol{\theta})-\sum_{\mathbf{z}} q(\mathbf{z})\{\ln p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta})-\ln q(\mathbf{z})\} \\
&=-\sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta})}{q(\mathbf{z})} \\
&= D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) ) \ge 0
\end{aligned} $
這個 gap 就是 KL divergence between 
如果能找到 
Log likelihood function 可以分為兩個部分: lower bound + gap
從 Jensen's inequality 得到 
如果
 does NOT provide any information of
does NOT provide any information of 
假設 
such that 
Lower bound 就變成原來的 log-likelihood function.
$latex \begin{aligned}
\mathcal{L}(q, \boldsymbol{\theta}) &= \sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}{q(\mathbf{z})}\\
&= \sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{o} \mid \boldsymbol{\theta}) p(\mathbf{z} \mid \boldsymbol{\theta})}{q(\mathbf{z})} \\
&= \sum_{\mathbf{z}} q(\mathbf{z}) \ln p(\mathbf{o} \mid \boldsymbol{\theta})\\
&= \ln p(\mathbf{o} \mid \boldsymbol{\theta})
\end{aligned} $
$latex \begin{aligned}
\mathcal{L}(q, \boldsymbol{\theta}) &= \sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}{q(\mathbf{z})}\\
&= \sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) p(\mathbf{o} \mid \boldsymbol{\theta})}{q(\mathbf{z})} \\
&= \sum_{\mathbf{z}} q(\mathbf{z}) \ln p(\mathbf{o} \mid \boldsymbol{\theta})\\
&= \ln p(\mathbf{o} \mid \boldsymbol{\theta})
\end{aligned} $
What is the mutual information of
Lower bound
Lower bound 其實可以視為 MLE of complete data,對應 EM algorithm 的 M step.
Gap 可以視為從 observables 推論出 unobservables, i.e. incomplete/hidden data, 對應 EM algorithm 的 E step.
Lower bound 包含兩個部分: (1) log-likelihood of complete data (both
這兩個部分剛好對應 EM algorithm 的 E-step and M-step.



 is fixed
is fixed我們先看 M-step, 因為這和 MLE estimate
$latex \begin{aligned}
\mathcal{L}\left(q^{(t+1)}, \boldsymbol{\theta}\right) &=\sum_{\mathbf{z}} q^{(t+1)}(\mathbf{z}) \ln \frac{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}{q^{(t+1)}(\mathbf{z})} \\
&=\sum_{\mathbf{z}} q^{(t+1)}(\mathbf{z}) \ln p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})-\underbrace{\sum_{\mathbf{z}} q^{(t+1)}(\mathbf{z}) \ln q^{(t+1)}(\mathbf{z})}_{\text {const. }}
\end{aligned} $
注意 M-Step 和完整 data 的 MLE 思路如下非常接近,只加了對
上式微分等於 0 就可以解 
另一個常見的寫法
注意 M-Step 是 maximize lower bound, 並不等於 maximize 不完整 data 的 MLE,因為還差了一個 gap function (i.e. KL divergence), which is also
 is fixed
is fixed以上 KL divergence 大於等於 0,所以 maximize lower bound 就要讓 要選擇
同樣 E-Step 深具物理意義,就是猜 incomplete/hidden data distribution based on 已知的 observables 和 iterative
例如問題四 E-Step 就是計算
我們可以把 conditional distribution 改成 joint distribution 如下。兩者都可以用來解 E-Step.
In summary: M-Step maximize the lower bound; E-Step close the gap
E-Step
M-Step
Define new E-Step (plug E-Step to M-Step)
$latex \begin{aligned}
Q(\theta^{t+1} | \theta^{t}) &= \sum_{\mathbf{z}} p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}^{(t)}) \ln p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta}^{t+1}) \\
&= \int d \mathbf{z} \, p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}^{(t)}) \ln p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta}^{t+1})
\end{aligned} $
new M Step
搞 machine learning 很多是物理學家 (e.g. Max Welling), 習慣用物理觀念套用於 machine learning. 常見的例子是 training 的 momentum method. 另一個是 energy/entropy loss function. 此處我們看的是類似 energy loss function.
我們從 gap 開始
$latex \begin{aligned}
\ln p(\mathbf{o} \mid \boldsymbol{\theta}) &= \mathcal{L}(q, \boldsymbol{\theta}) + D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) ) \\
&= \sum_{\mathbf{z}} q(\mathbf{z}) \ln \frac{p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta})}{q(\mathbf{z})} + D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) ) \\
&= \sum_{\mathbf{z}} q(\mathbf{z}) \ln p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta}) + \sum_{\mathbf{z}} -q(\mathbf{z}) \ln {q(\mathbf{z})}+ D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) ) \\
&= E_{q(z)} \ln p(\mathbf{o}, \mathbf{z} \mid \boldsymbol{\theta}) + H(q) + D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid \mathbf{o}, \boldsymbol{\theta}) ) \\
\end{aligned} $
where H(q) is the entropy of q, 第一項是負的,第二項和第三項是正的。
我們用一個例子來驗證
q = {0 or 1} with 50% chance, =>
H(q) = 1 (bit) or ln (?) > 0
Eq(z) ln p(o, z) = -(0.5 (o-u1)2 + 0.5 (o-u2)2 ) / sqrt(2pi) < 0
此處我們 switch to [@poczosCllusteringEM2015] notation.


![\theta = [\mu_1, \cdots, \mu_K, \pi_1, \cdots, \pi_K, \Sigma_1, \cdots, \Sigma_K]](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5B%5Cmu_1%2C+%5Ccdots%2C+%5Cmu_K%2C+%5Cpi_1%2C+%5Ccdots%2C+%5Cpi_K%2C+%5CSigma_1%2C+%5Ccdots%2C+%5CSigma_K%5D+&bg=ffffff&fg=111111&s=0&c=20201002)

重寫上式:
$latex \begin{aligned}
\ln p(D \mid \boldsymbol{\theta}^t) &= \sum_{\mathbf{z}} q(\mathbf{z}) \ln p(D, \mathbf{z} \mid \boldsymbol{\theta}^t) + \sum_{\mathbf{z}} -q(\mathbf{z}) \ln {q(\mathbf{z})}+ D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid D, \boldsymbol{\theta}^t) ) \\
&= E_{q(z)} \ln p(D, \mathbf{z} \mid \boldsymbol{\theta}) + H(q) + D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid D, \boldsymbol{\theta}) ) \\
&= F_{\theta^t} (q(\cdot), D) + D_{\mathrm{KL}}(q(\mathbf{z}) \| p(\mathbf{z} \mid D, \boldsymbol{\theta}) )
\end{aligned} $

如果 
The EM algorithm can be summzied as argmax Q!!

We can prove


Use multiple, randomized initialization in practice.
EM algorithm 一個問題是對於複雜的問題沒有 close from p(z|x), then toast!
我們之前的 E-Step 是猜 joint distribution,
|
|
|
|---|---|---|
|
a | 5a |
|
3b | b |
如果用上述的 conditional distribution 可以細膩的看每一個 data.
對於所有 
$latex q(t \mid s_0, a, b)=\left\{\begin{array}{l}
q\left(t_{0}\right)=p\left(t_{0} \mid s_{0}, a, b\right)=\frac{a}{a+3 b} \\
q\left(t_{1}\right)=p\left(t_{1} \mid s_{0}, a, b\right)=\frac{3 b}{a+3 b}
\end{array}\right. $
對於所有 
$latex q(t \mid s_1, a, b)=\left\{\begin{array}{l}
q\left(t_{0}\right)=p\left(t_{0} \mid s_{1}, a, b\right)=\frac{5a}{5 a+ b} \\
q\left(t_{1}\right)=p\left(t_{1} \mid s_{1}, a, b\right)=\frac{b}{5 a+ b}
\end{array}\right. $
對於所有 
$latex q(s \mid t_0, a, b)=\left\{\begin{array}{l}
q\left(s_{0}\right)=p\left(s_{0} \mid t_{0}, a, b\right)=\frac{1}{6} \\
q\left(s_{1}\right)=p\left(s_{1} \mid t_{0}, a, b\right)=\frac{5}{6}
\end{array}\right. $
對於所有 
$latex q(s \mid t_1, a, b)=\left\{\begin{array}{l}
q\left(s_{0}\right)=p\left(s_{0} \mid t_{1}, a, b\right)=\frac{3}{4} \\
q\left(s_{1}\right)=p\left(s_{1} \mid t_{1}, a, b\right)=\frac{1}{4}
\end{array}\right. $
再來是問題二的 M-Step
最後再把所有 dataset 的 weighted sum 
















因此可以使用完整 data 的 MLE estimation:
Go through GMM example.
下一步 go through HMM model or simplest z -> o graph model.
Unsupervised learning (UL) 簡單說就是 learning without label. 常見的 UL 包含降維 (e.g. PCA) 或是 clustering (e.g. K-means). UL 比起 supervised learning (SL) 更難以捉摸。
一個常引述的原因是 UL 的結果比較主觀,因為沒有 label 也就沒有標準答案。但這並不意味沒有 loss function. 當然我們需要 loss function 才能 optimization. 但是
本文聚焦在 clustering, 目標是
一個問題是如何定義 "similarity"? 常見幾種做法:
Cosine/angular similarity: 


Distance similarity: 

Exponential similarity: 在很多情況,similarity 需要比 cosine, L1, or L2 函數更 nonlinear 的函數。例如在 downstream task 分類問題,不同類別(如車子和行人)可能天差地遠。因此可以把原來的 cosine, L1, or L2 函數結合 exponential 函數產生:
 或是
或是  這和 softmax function 非常相像。特別適合結合 (deep) neural network 用於分類問題。
這和 softmax function 非常相像。特別適合結合 (deep) neural network 用於分類問題。 or
or  這似乎特別適合 (shallow) machine learning 的 kernel function (e.g. kernel-SVM, kernel-PCA), 同樣大多用於分類問題。
這似乎特別適合 (shallow) machine learning 的 kernel function (e.g. kernel-SVM, kernel-PCA), 同樣大多用於分類問題。直覺上 distance similarity 似乎比 angular similarity 更精確。實務上還是要看 downstream task. 例如在 face recognition task, angular similarity (with margin) 是主流的做法。

本文討論的 clustering 聚焦在 distance similarity (K-means) and exponential distance similarity (GMM).
K-means 問題的陳述非常簡單: Given a set of observations (

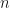


where 

上式的重點 K-means 是 minimize similarity distance, 就是 High intra-class similarity, 不管 Low inter-class similarity.
另外一派注重 low inter-class similarity (or maximum margin similarity), i.e. angular similarity with margin 此處不表,可以參考別文。
K-means cost function(如下式)沒有 close form solution. 因為 


後面會提到,這是 EM algorithm 的特例。對於每一個 

下圖是一個 

Step 1: initialization. 先隨便選擇 3 個 

Step 2: (hard) assign each 
具體做法有兩種: (1)計算

Step 3: Re-estimate the cluster centers 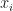

Repeat Step 2 (re-assignment) and step 3 (re-estimate) to minimize the cost function continuously. **Stop when the re-assignment do NOT change anymore.


Input
Initialize
cluster centers (randomly if necessary)Iterate
cluster centers (aka the centroid or mean), by assuming the memberships found above are correct.Termination
objects changed membership in the last iteration, exit.注意以上的算法並沒有保證一定會找到 global minima! 如果 initial guess 不理想,很容易陷入 local minima. 因此需要 randomize initial guess many times and find a better (local) minima.
我們可以用物理的觀念來解釋,定義 potential function
where 

and 
K-means algorithm (coordinate descent on F)
(1) Expectation step (re-assignment): fix
(2) Maximization step (re-center): fix 
GMM 可以視為 K-means 的進化版。 K-means 要求每個 data point 



K-means: hard assignment: 每一個 
GMM: soft assignment: 每一個
如果限制 



如何決定 probability? 此時 exponential similarity 就派上用場。GMM 使用 Gaussian distribution, 對應 exponential (L2) distance similarity.
Gaussian mixture models (GMMs) 可以用以下的 graph model 代表。 data point 都是一個 




我們會 given 一堆
observed data = summation of mixture component (Gaussian) * mixture proportion (


先考慮一個假的 GMM: assume ![\theta=\left[\mu_{1}, \ldots, \mu_{K}, \Sigma_{1}, \ldots, \Sigma_{K}, \pi_{1}, \ldots, \pi_{K}\right]](https://s0.wp.com/latex.php?latex=%5Ctheta%3D%5Cleft%5B%5Cmu_%7B1%7D%2C+%5Cldots%2C+%5Cmu_%7BK%7D%2C+%5CSigma_%7B1%7D%2C+%5Cldots%2C+%5CSigma_%7BK%7D%2C+%5Cpi_%7B1%7D%2C+%5Cldots%2C+%5Cpi_%7BK%7D%5Cright%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
考慮 clustering based on posteriors (i over j):
這代表 ”Quadratic Decision Boundary", 就是拋物線 boundary 如下圖。

如果所有

GMM 並沒有真的 boundary, 也不是 hard assignment, 此處只是 for illustration purpose.
現實世界
GMM 問題其實是一個 maximum likelihood problem to estimate
$latex \begin{aligned}
\arg \max _{\theta} \prod_{j=1}^{n} P\left(x_{j} \mid \theta\right) &=\arg \max _{\theta} \prod_{j=1}^{n} \sum_{i=1}^{K} P\left(z=i, x_{j} \mid \theta\right) \\
&=\arg \max _{\theta} \prod_{j=1}^{n} \sum_{i=1}^{K} P\left(z=i \mid \theta\right) p\left(x_{j}\mid z=i , \theta\right) \\
&=\arg \max _{\theta} \prod_{j=1}^{n} \sum_{i=1}^{K} \pi_{i} \frac{1}{\sqrt{\left|2 \pi \Sigma_{i}\right|}} \exp \left[-\frac{1}{2}\left(x_{j}-\mu_{i}\right)^{T} \Sigma_{i}^{-1}\left(x_{j}-\mu_{i}\right)\right]
\end{aligned} $
上述方程式非常複雜,有幾種可能的解法
EM 其實和原來 K-means 的 iterative solution 有異曲同工之妙。
K-means: (1) fix
In EM, 我們基本上 reuse 以上的 recipe 稍加修改,再取一個 fancy 名字:E-optimizaiton and M-optimization for EM algorithm, 就成為 10 大最有影響力的演算法。
修改的方法:(1) fix 
Step (1) 稱為 E-step (Expectation); (2) 稱為 M-step (Maximization).
 相同且已知。另外 為已知!
相同且已知。另外 為已知!假設 unknowns are: ![\theta = [\mu_1, \mu_2, \cdots, \mu_K]](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5B%5Cmu_1%2C+%5Cmu_2%2C+%5Ccdots%2C+%5Cmu_K%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
$latex \begin{aligned}
p\left(x_{1}, \ldots, x_{n} \mid \mu_{1}, \ldots \mu_{K}\right)&=\prod_{j=1}^{n} p\left(x_{j} \mid \mu_{1}, \ldots, \mu_{K}\right) \quad \text { Independent data }\\
&=\prod_{j=1}^{n} \sum_{i=1}^{K} p\left(x_{j}, z=i \mid \mu_{1}, \ldots, \mu_{K}\right) \quad \text { Marginalize over class }\\
&=\prod_{j=1}^{n} \sum_{i=1}^{K} p\left(x_{j} \mid z=i, \mu_{1}, \ldots, \mu_{K}\right) p\left(z=i\right) \\
&\propto \prod_{j=1}^{n} \sum_{i=1}^{K} \exp \left(-\frac{1}{2 \sigma^{2}}\left\|x_{j}-\mu_{i}\right\|^{2}\right) \pi_{i} \Rightarrow \text { learn } \mu_{1}, \mu_{2}, \ldots \mu_{\mathrm{K}}
\end{aligned} $
比較一下 K-means 的 object function
如果把上上式 GMM 的 soft assignment 限制成 hard assignment, 再取 log on the likelihood function and re-grouping. GMM 和 K-means 似乎完全等價!(to be proved)
接下來我們示範用 iterative method (EM algorithm) 解問題。
![\theta^0 = [\mu^0_1, \mu^0_2, \cdots, \mu^0_K]](https://s0.wp.com/latex.php?latex=%5Ctheta%5E0+%3D+%5B%5Cmu%5E0_1%2C+%5Cmu%5E0_2%2C+%5Ccdots%2C+%5Cmu%5E0_K%5D+&bg=ffffff&fg=111111&s=0&c=20201002) ( 為已知). => same as K-means
( 為已知). => same as K-means通常隨機的結果不好,我們可以先用 K-Means to get a good initialization.
to 其實就是在 minimize cost function by fixing
做法很直觀,因為所有 Gaussian distribution variance 都一樣,距離就是唯一的決定因素。基本就是每一個
$latex \begin{aligned}
P\left(z=i \mid x_{j}, \theta^{t-1}\right) &=P\left(z=i \mid x_{j}, \mu_{1}^{t-1}, \ldots, \mu_{K}^{t-1}\right) \\
& \propto P\left(x_{j} \mid z=i, \mu_{1}^{t-1}, \ldots, \mu_{K}^{t-1}\right) P\left(z=i\right) \\
& \propto \exp \left(-\frac{1}{2 \sigma^{2}}\left\|x_{j}-\mu_{i}^{t-1}\right\|^{2}\right) \pi_{i} \\
=& \frac{\exp \left(-\frac{1}{2 \sigma^{2}}\left\|x_{j}-\mu_{i}^{t-1}\right\|^{2}\right) \pi_{i}}{\sum_{i=1}^{K} \exp \left(-\frac{1}{2 \sigma^{2}}\left\|x_{j}-\mu_{i}^{t-1}\right\|^{2}\right) \pi_{i}}
\end{aligned} $
Equivalent to assigning clusters to each data point in K-means in a soft way

其實也是在 minimize the cost function with fixed
直觀說就是機率 
檢查一下,如果是 hard assignment,
實務上要計算
$latex
Q\left(\theta, \theta^{t}\right)=E_{Z}\left[\log \left(p\left(X, Z \mid \theta^{t}\right)\right)\right]
$
Maximize Q function 可以證明同時也 maximize likelihood function.
$latex
\theta^{t+1}=\arg \max _{\theta}\left[Q\left(\theta, \theta^{t}\right)\right]
$
此處不涉入細節,可以參考 [@alliliShortTtutorial2010].
需要迭代, and 也需要迭代E-step
M-step
這是 special case.
Not finding the path, but find the initial distribution 

機器學習的起手式是 MNIST 的手寫數字辨識率,這是 supervised learning. 使用的 Neural network 是 discriminative model, 可以是 MLP (multi-layer perceptron) 或是 CNN.
另一個機器學習的分支是 MNIST 影像 dimension reduction/compression, reconstruction, denoise, 這是 unsupervised learning, 也稱為 self-supervised learning. 使用的 neural network (decoder) 是 generative model, 可以是 autoencoder (AE) 以及變形 (sparse AE, convolution AE, variational AE, etc.) 或是更 fancy 的 GAN, 如下圖。
AE 以及變形在 training 都用 encoder-decoder 架構,self-supervised training.
本文主要聚焦在 VAE. VAE 其實和 AE 有很大的差別。AE 可以視為 (nonlinear) dimension reduction 如下圖,本質上很 PCA 非常類似。Hinton 發表在 Science 的 autoencoder paper 可說是開山之作[@hintonReducingDimensionality2006]. AE paper 引入的 encoder-decoder 架構,至今如 transformer 持續使用中。Encoder-decoder 的重要性在機器學習無所不在。大概只有 GAN 的 discriminator-generator 才創造另一種新的架構,普遍性還是比不上 encoder-decoder。

下圖是 MNIST 經過 AE 降維後再影射到 2D 空間的(樣本)分佈。這個分佈可以幫助判斷降維 feature extraction 的好壞。
原則上不同數字(0-9)對應的分佈愈集中代表 intra-class 的 variation 愈小,降維的 feature extraction 有抓到同一類別 “dominating feature". Inter-class 分佈愈分開,降維的 feature extraction 有抓到不同類別的 "differentiated feature"。
這是分類網絡最大的挑戰,maximize inter-class distribution distance and minimize intra-class distribution variation. AE 降維網絡 (encoder) 提供了這個工具。之後的各種變形 (CNN AE, sparse AE, etc.) 都是 AE 延伸。
AE 一個大問題:我們無法控制這個樣本分佈。為什麼這是一個大問題?因為無法控制樣本分佈就無法用於 generative model! 試試用 AE generate 一個數字或是人臉。基本無從下手。

簡單來說就是把 AE 無法控制的樣本分佈 
VAE 雖然繼承了 AE encoder-decoder 架構,以及 unsupervised/self-supervised training procedure, 但和 AE 卻有本質的差異。簡單來說
* 最基本/重要:VAE 是 probabilistic encoder/decoder, AE 則是 deterministic encoder/decoder. VAE decoder 是 true generative model, 可以用在 image generation 重要的功能。
* Inference: AE 一般使用 encoder 降維,或是 encoder-decoder denoise image. VAE 一般使用 decoder for image generation.
* z 是 Gaussian distribution with mean/variance.


VAE training 部分是最難理解的部分。因為會加入 “random sample”, 
我們可以直觀理解 by setting 


另一個角度,VAE (encoder) 可以想成分布變換。接下來詳細說明。在這個 picture 中 

目前主流的觀點是 (2),因為應用廣泛。問題是如何在 training 時達成這種分布變換?
用下圖表示我們想要達成的目的。
 (sample) 變換成
(sample) 變換成  , sample distribution 和原來的 input
, sample distribution 和原來的 input  sample distribution 相等。
sample distribution 相等。 生成目標數據
生成目標數據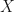 的模型,但是實現上有所不同。更準確地講,它們是假設了服從某些常見的分布(比如正態分布或均勻分布),然後希望訓練一個模型
的模型,但是實現上有所不同。更準確地講,它們是假設了服從某些常見的分布(比如正態分布或均勻分布),然後希望訓練一個模型  ,這個模型能夠將原來的機率分布映射到訓練集的機率分布,也就是說,它們的目的都是進行分布之間的變換。 的維度遠小於
,這個模型能夠將原來的機率分布映射到訓練集的機率分布,也就是說,它們的目的都是進行分布之間的變換。 的維度遠小於  or ,因此 generator (or decoder) 同時執行升維和分布變換。
or ,因此 generator (or decoder) 同時執行升維和分布變換。
重點是如何定義 loss function.
假設 




雖然遇到困難,但還是要想辦法解決的。GAN的思路很直接粗獷:既然沒有合適的度量(loss function?),那我乾脆把這個度量也用神經網絡訓練出來吧。就這樣,WGAN就誕生了,詳細過程請參考《互懟的藝術:從零直達WGAN-GP》。而VAE則使用了一個精緻迂迴的技巧。[@suVariationalAutoencoder2018]
首先我們有一批數據樣本 {
此時 


問題在哪裡?在 training!
如果如上圖的話,我們其實完全不清楚:究竟經過重新採樣出來的



其實,在整個VAE模型中,我們並沒有去使用 

具體來說,給定一個真實樣本


上圖和上上圖差別在哪裡?就是均值 (mean) 和方差 (variance)在 after training finished, i.e. inference 是一個固定值(和
事實上,在論文《Auto-Encoding Variational Bayes》的應用部分,也特別強調了這一點。注意下式中的 

In this case, we can let the variational approximate posterior be a multivariate Gaussian with a diagonal covariance structure:
論文中的上式是實現整個模型的關鍵,不知道為什麼很多教程在介紹VAE時都沒有把它凸顯出來。儘管論文也提到
順便說明為什麼 

我們知道一堆正態分布的 weighted sum 還是正態分布,所以
回到本文,這時候每一個
那我怎麼找出專屬於
於是我們構建兩個神經網絡
比較 AE encoder 和 VAE encoder
dependent latent variable ; VAE 產生兩個 input dependent latent variables, and
and  .
.我們選擇擬合

讓我們來思考一下,根據上圖的訓練過程,最終會得到什麼結果。
首先,我們希望重構
說白了,模型會慢慢退化成普通的AutoEncoder,噪聲不再起作用。
這樣不就白費力氣了嗎?說好的生成模型呢?
別急別急,其實VAE還讓所有的
這樣我們就能達到我們的先驗假設:
Really? 這代表 


How? By define the loss function!
那怎麼讓所有的
因為它們分別代表了均值
這裡的


and  ) 和
) 和  差距。
差距。顯然,latent loss 也可以分兩部分理解:
$latex \begin{array}{l}
\mathcal{L}_{\mu, \sigma^{2}}=\mathcal{L}_{\mu}+\mathcal{L}_{\sigma^{2}} \\
\mathcal{L}_{\mu}=\frac{1}{2} \sum_{i=1}^{d} \mu_{(i)}^{2}=\frac{1}{2}\left\|f_{1}(X)\right\|^{2} \\
\mathcal{L}_{\sigma^{2}}=\frac{1}{2} \sum_{i=1}^{d}\left(\sigma_{(i)}^{2}-\log \sigma_{(i)}^{2}-1\right)
\end{array} $







注意任一 



除了 latent loss, XAE (AE, VAE, SAE, CAE) 的基本 loss term 是重構誤差(reconstruction loss)。 所以 VAE training 完整的 loss 包含 latent loss 加上 reconstruction loss, 見 Appendix A code.
最後是實現模型的一個技巧,reparameterization trick。其實很簡單,就是我們要從
這說明 

這時候我們得到:從 



於是,我們將從
Forward path
兩者都是 dimension vector/tensor. from , compute  . 的 dimension? in decoder to reconstruct
. 的 dimension? in decoder to reconstruct 
Compute loss term 包含 reconstruction loss and latent loss

Backward path (自動微分)
, given the fixed sample and based on  , 可以 update and
, 可以 update and  .
.以下 from [@suVariationalAutoencoder2018], 很好總結 VAE 的本質。
VAE的本質是什麼?VAE雖然也稱是AE(AutoEncoder)的一種,但它的做法(或者說它對網絡的詮釋)是別具一格的。在VAE中,它的Encoder有兩個,一個用來計算均值,一個用來計算方差,這已經讓人意外了:Encoder不是用來Encode的,是用來算均值和方差的,這真是大新聞了,還有均值和方差不都是統計量嗎,怎麼是用神經網絡來算的?
事實上,VAE從讓普通人望而生畏的變分和貝葉斯理論出發,最後落地到一個具體的模型中,雖然走了比較長的一段路,但最終的模型其實是很接地氣的:它本質上就是在我們常規的自編碼器的基礎上,對encoder的結果(在VAE中對應著計算均值的網絡)加上了「高斯噪聲」,使得結果decoder能夠對噪聲有 robustness;而那個額外的KL loss(目的是讓均值為0,方差為1),事實上就是相當於對encoder的一個正則項,希望encoder出來的東西均有零均值。
那另外一個encoder(對應著計算方差的網絡)的作用呢?它是用來動態調節噪聲的強度的。直覺上來想,當decoder還沒有訓練好時(重構誤差遠大於KL loss),就會適當降低噪聲(KL loss增加),使得擬合起來容易一些(重構誤差開始下降);反之,如果decoder訓練得還不錯時(重構誤差小於KL loss),這時候噪聲就會增加(KL loss減少),使得擬合更加困難了(重構誤差又開始增加),這時候decoder就要想辦法提高它的生成能力了。

說白了,重構的過程是希望沒噪聲的,而KL loss則希望有高斯噪聲的,兩者是對立的。所以,VAE跟GAN一樣,內部其實是包含了一個對抗的過程,只不過它們兩者是混合起來,共同進化的。從這個角度看,VAE的思想似乎還高明一些,因為在GAN中,造假者在進化時,鑒別者是安然不動的,反之亦然。當然,這只是一個側面,不能說明VAE就比GAN好。GAN真正高明的地方是:它連度量都直接訓練出來了,而且這個度量往往比我們人工想的要好(然而GAN本身也有各種問題)。
https://ithelp.ithome.com.tw/articles/10188453
Variational Autoencoder 直接從 Github 上找實作來試試看,並用 MNIST 的資料來重現。
在 encoder 一開始的地方和 Autoencoder 一樣,循序的降維.這裡定義了維度從 784 維到 500 維到 200(501?) 維再到 2 維.
n_z = 2 #Dimension of the latent space
# Input
x = tf.placeholder("float", shape=[None, 28*28]) #Batchsize x Number of Pixels
y_ = tf.placeholder("float", shape=[None, 10]) #Batchsize x 10 (one hot encoded)
# First hidden layer
W_fc1 = weights([784, 500])
b_fc1 = bias([500])
h_1 = tf.nn.softplus(tf.matmul(x, W_fc1) + b_fc1)
# Second hidden layer
W_fc2 = weights([500, 501]) #501 and not 500 to spot errors
b_fc2 = bias([501])
h_2 = tf.nn.softplus(tf.matmul(h_1, W_fc2) + b_fc2)
接下來就是有趣的地方了,再進入 2 維前它把前面經過低維權重輸出的向量複製兩份,來建立 Gaussian,而且一份做成 mean 一份做成 stddev …
再來把它轉成二維的 code layer
# Parameters for the Gaussian
z_mean = tf.add(tf.matmul(h_2, weights([501, n_z])), bias([n_z]))
z_log_sigma_sq = tf.add(tf.matmul(h_2, weights([501, n_z])), bias([n_z]))
Samples from a Gaussian using the given mean and the std. The sampling is done by adding a random number ensuring that backpropagation works fine.
batch_size = 64
eps = tf.random_normal((batch_size, n_z), 0, 1, dtype=tf.float32) # Adding a random number
z = tf.add(z_mean, tf.mul(tf.sqrt(tf.exp(z_log_sigma_sq)), eps)) # The sampled z
W_fc1_g = weights([n_z, 500])
b_fc1_g = bias([500])
h_1_g = tf.nn.softplus(tf.matmul(z, W_fc1_g) + b_fc1_g)
W_fc2_g = weights([500, 501])
b_fc2_g = bias([501])
h_2_g = tf.nn.softplus(tf.matmul(h_1_g, W_fc2_g) + b_fc2_g)
x_reconstr_mean = tf.nn.sigmoid(tf.add(tf.matmul(h_2_g, weights([501, 784])), bias([784])))
reconstr_loss = -tf.reduce_sum(x * tf.log(1e-10 + x_reconstr_mean) + (1-x) * tf.log(1e-10 + 1 - x_reconstr_mean), 1)
latent_loss = -0.5 * tf.reduce_sum(1 + z_log_sigma_sq - tf.square(z_mean) - tf.exp(z_log_sigma_sq), 1)
cost = tf.reduce_mean(reconstr_loss + latent_loss) # average over batch
# Use ADAM optimizer
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
由於我們考慮的是各分量獨立的多元正態分布,因此只需要推導一元正態分布的情形即可,根據定義我們可以寫出
$latex \begin{aligned}
& K L\left(N\left(\mu, \sigma^{2}\right) \| N(0,1)\right) \\
=& \int \frac{1}{\sqrt{2 \pi \sigma^{2}}} e^\frac{-(x-\mu)^{2}}{2 \sigma^{2}}\left(\log \frac{e^{-(x-\mu)^{2} / 2 \sigma^{2}} / \sqrt{2 \pi \sigma^{2}}}{e^{-x^{2} / 2} / \sqrt{2 \pi}}\right) d x\\
=& \int \frac{1}{\sqrt{2 \pi \sigma^{2}}} e^\frac{-(x-\mu)^{2}}{2 \sigma^{2}} \log \left\{\frac{1}{\sqrt{\sigma^{2}}} \exp \left\{\frac{1}{2}\left[x^{2}-(x-\mu)^{2} / \sigma^{2}\right]\right\}\right\} d x \\
=& \frac{1}{2} \int \frac{1}{\sqrt{2 \pi \sigma^{2}}} e^\frac{-(x-\mu)^{2}}{2 \sigma^{2}} \left[ -\log \sigma^{2}+x^{2}-(x-\mu)^{2} / \sigma^{2}\right] d x
\end{aligned} $
整個結果分為三項積分,第一項實際上就是

Durr, Oliver. 2016. “VAE Tutorial.” GitHub. November 25, 2016. https://github.com/oduerr/dl_tutorial.
Hinton, G. E., and R. R. Salakhutdinov. 2006. “Reducing the Dimensionality of Data with Neural Networks.” Science 313 (5786):504–7. https://doi.org/10.1126/science.1127647.
Su, Jianlin. 2018. “Variational Autoencoder 1:原来是这么一回事 – 科学空间|Scientific Spaces.” March 18, 2018.
https://kexue.fm/archives/5253.
物理學最早從現象的觀察,歸納出定律(law) – 例如光學 Snell's law,牛頓力學定律,萬有引力定律,電磁學的庫倫定律、安培定律、法拉第定律、Lawrence 定律、最終整合成 Maxwell's equation 的電磁學定律。再由這些定律找出更基本,更統一且具有美感的原理。
一般認為物理學的兩大基本原理是:最小作用原理和對稱性原理。 可以從這兩大基本原理推論出定律。再由定律解釋各種物理現象,如下圖。(相對性原理是對稱性原理的一種?)

Step 1: 找到或是猜到這個系統的 Lagrangian, L. "作用 (action)"一般是 Lagrangian 的時間積分。以古典力學為例
where 


Step 2A: 使用最小作用原理,用變分法 (calculus of variation) 於 action, 就是用 Euler-Lagrange equation, 得到“自然定律一”,一般是運動方程式。例如應用於古典力學可以得到牛頓力學定律 [@sufeifanDerivationClassic2019]。應用於電磁學可以得到 EM Wave equation. 顯然最小作用原理和 scaling/coupling constant 無關(最小值乘常數或加常數還是最小值),因此需要確認常數和定律的 consistency.
Step 2B: 使用對稱性原理,用 Noether Theorem 找到對應的守恆量,”自然定律二“。例如 time symmetry 對應能量守恆定律,space symmetry 對應動量守恆定律,rotation symmetry 對應角動量守恆定律。電磁場的 gauge symmetry 對應電荷守恆定律。更高級的場論(field theory) 的對稱性對應完整的理論,例如 U(1) 對稱性對應電磁場理論。U(1) x U(1) 對應電弱場理論。
Step 3: 自然定律還要加上 (time) initial condition 和 (space) boundary condition 才能得到或解釋自然現象。例如自由落體和行星運動都遵守牛頓萬有引力定律,但因為 initial condition 而有不同的運動。同樣微波爐和手機都遵守 Maxwell equations, 但因為 boundary condition 而有不同的作用。
最小作用量用原理貫穿物理學的發展。一個問題是最小作用原理 (least action principle, LAP or PLA) 比較抽象。 一種粗略的說法:作用的抽象觀念(或單位)是 (energy)x(time), 代表大自然不偏愛能量或時間,而是兩者的乘積。 但為什麼古典力學 action 積分中的 Lagrangian = (動能-位能)? 這並不直觀。再加上作用是對時間的積分。人是視覺的動物,對於空間幾何的掌握高於時間運動。最好能把最小作用原理轉換為幾何原理詮釋,類似最短距離路徑或是最短時間路徑,比較能抓住其中物理意義。
順便一提,希臘的芝諾 (Zino) 和他的老師否定運動存在,所以才提出芝諾悖論:「阿奇里斯追不上烏龜」和「飛矢不動」等等,間接暗示人對時間和運動的主觀性。這也導致後來馬赫、愛因斯坦對於“時空”開創性的看法。
我之前花了一些時間把一些定律和幾何原理連結。其實這也是相對論的基本思想。時空相對性原理 (i.e. Lorentz transform) 就是"時空坐標系“的微分幾何的不變量 (ds). 廣義相對論方程式就是彎曲時空最短路徑原理(geodesic, 測地線)。同樣幾何光學可以轉換成最短時間原理。但只能片段串在一起,沒有貫穿所有理論。
注意,最短時間原理雖然包含時間,但這裡的時間只是 derived parameter, 距離除以速度(或是 momentum, p, 假設質量=1), i.e. 
最短時間原理是找 


古典力學的最小作用原理或是動力學定律反而比較困難找到幾何原理,因為在 (x(t), t) ”慣性座標系” t 是無所不在的自變數。必須轉成 (p(q), q) “phase space”, t 被隱藏在 p 內,才會被踢出幾何原理。用微分幾何的術語,才能定義微分幾何不變量 ds 和測地線 (geodesic).
Maupertuis (其實應該是 Euler) 原理可以視為幾何化最小作用原理。在歷史上是較早的最小作用原理。不過有一些限制(固定初速和能量守恆,位能只和位置相關),而且不含時間不方便用於解運動方程式。但比較直觀,容易理解,後面會詳細介紹。[@wikiMaupertuisPrinciple2020] and [@fowlerMaupertuisPrinciple2009]
假設考慮粒子在某個平面中從某個初始點和時間 



一般的最小作用原理可以得出 
限制 time and space boundary condition


我們用最簡單的 1D 直線自由運動為例,說明什麼是最小作用原理。
自由運動代表只有動能 
最小作用原理:固定初始點和時間 


注意最小作用原理並沒有假設能量守恆。如果用上能量守恆,這個例子就不用算了。能量守恆是由對稱性原理(T-invariant)得到。
此處假設 


1D 直線運動的 boundary condition 非常簡單,就是
對應下圖二的面積積分是一個定值。

使用 Cauchy-Schwarz 不等式
等號成立時 
加上均勻位能條件:
同樣 boundary condition
因此 action S
…
所以 action
同樣用 Cauchy-Schwarz 不等式
等號成立時 
如預期,這是等加速度運動!
雖然我們用 Cauchy-Schwarz 不等式找出自由運動和一階位能場的解,但並沒有什麼物理意義。
二階以及更複雜的位能函數很難用 Cauchi-Schwarz 不等式或是基本的代數求解,需要用到變分法求解。不過我們後面可以用幾何化的最小作用原理,結合(微分)幾何提供一些 insight.
接下來我們尋找另一種最小作用原理。這次不固定時間,但是固定了空間的起點和終點,但允許最終時間可能有所變化。也就是 (



實際上我們也假設整個 path 能量守恆。因此沒有時間的 explicit dependency. 一般可以用 time-independent Hamiltonian function 
因為 



![\vec{p} = [p_x, p_y]](https://s0.wp.com/latex.php?latex=%5Cvec%7Bp%7D+%3D+%5Bp_x%2C+p_y%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
![\vec{q} = [x, y]](https://s0.wp.com/latex.php?latex=%5Cvec%7Bq%7D+%3D+%5Bx%2C+y%5D+&bg=ffffff&fg=111111&s=0&c=20201002)



這意味我們必須限制在具有固定能量 
如果果嶺是平面,所有初速
Q. 如何定義新的作用,有比較明確的物理或幾何意義? Abbreviated action, no time dependency given initial speed. 和原來的 action 不同,更有幾何意義。
Q. 如何定義新的最小作用原理?或者是否還有最小作用原理? Yes, 就是 Maupertuis 原理.
我們先定義 abbreviated action 如下。假設固定初速以及能量守恆,下式明顯只和路徑有關,和 t 無關,是一種幾何表示。
先檢查 

這和一般 action: energy * time = mv2 sec = kg (m/sec)2 sec = kg m2 /sec 一致。
再來 
如果是兩個速度(對應兩個位能),積分包含兩區。
先定義總能量 function (i.e. Hamiltonian):
把 Lagrangian 代入 action:
假設 
也就是說,一般的 action 



這個分解和波動方程式 (e.g. Maxwell wave function or Schrodinger wave) 的 separation of variables 把 time and spatial 分開有異曲同工之處。不過電磁波動方程式的 separation of variables 是乘法 
如果看量子力學波動方程式更明顯:
我們用一個簡單的例子確認上上式的正確性:Free particle (V=0) in the space. 假設能量守恆, i.e. 
可以簡單驗證 (sanity check):
Q: 為什麼上式是 

A: 同樣用 free particle 為例。Fixed 





其實
[@fowlerMaupertuisPrinciple2009] 推導如何從最小作用原理得到 Maupertuis 原理, 不過要再推敲一下。
從最小作用原理出發:在固定
以及 
再用 action 和 abbreviated action 的關係式

在不固定 
可以得到 Maupertuis 原理.
或是
Maupertuis 原理去除時間的相關性(i.e. p is p(q), not p(q,t) assuming initial velocity is fixed),變成空間原理, 也就是幾何的原理。是否有直觀物理意義? 3D space 的 free particle (V=0) 最小XX原理一定是直線,無法區分。我們用次簡單的 two potential regions (



由於能量守恆,high potential 對應 low speed, and vice versa.
橘線是最短距離,當然不是 Maupertuis 原理的路線。只是做為 baseline.
藍線是最短時間,對應的是 



紫線則是最小“作用”,此處的“作用”不是 Lagrange 或是 Hamilton action, 而是 abbreviated action,

這和最短時間原理的邏輯剛好相反。在高速運動的距離比較短,減少整體“作用”的積分。我們可以檢查紫線是否符合古典力學。

應該反過來,用微積分找出商數公式 (appendix)。得到結論是水平方向速度是定值。
我們直接用牛頓力學無外力時的動量守恆說明。牛頓力學的"力"可以視為 potential gradient. 下圖可以看出“力”只存在垂直方向,水平方向沒有 potential gradient, 因此沒有“力”。也因此水平方向的動量守恆。

這和幾何光學的 Snell's Law,或是最短時間原理,數學上剛好相反。

我們可以整理結論。高位能 → 低速 → 長距離; 低位能 → 高速 → 短距離
一個簡單的做法是重新定義幾何光學的 refractive index, n. 就可以 reuse 幾何光學的結果。 From Snell's law and the least "action", we can define refractive index n, either n(v) or n(1/v). There is nothing new, but we can reuse geometric optics results to motion.
注意現在沒有 t
1D 一階位能場 (
能量守恆要求:
Let 

2D 二階位能場 (
能量守恆要求:
Let

1D 的軌跡都是直線運動,(p,q)形成二維平面。給定位能函數和初速,只要用能量守恆就可以得到每一點的動能和動量 p, 用不到 Maupertuis 原理。
2D 的軌跡, (p,q) 形成四維空間。
再來是 2D 平面,如果是 uniform x-direction linear field => 拋物線。如果是重力場 (環形場), 則是圓形或是橢圓形。=> how to derive it from Maupertuis 原理?
Use 2 particles 4-dimension example? or generalized coordinates
如果空間不存在位能場 (
當空間存在位能場,古典的看法是位能場的梯度代表外力,這個外力會改變運動的軌跡,不再是直線。而是最小作用原理或是 Maupertuis 原理決定的曲線,如前所述。
另一種不同的看法,來自愛因斯坦的廣義相對論,質量(或能量,質能互換)造成空間彎曲,運動物體的軌跡其實還是“彎曲空間”的最短距離, geodesic. 如果加上時空座標,就變成一個存粹的(黎曼)幾何問題。此處我們不討論廣義相對論,只是借用彎曲空間的觀念致敬愛因斯坦。
 ; 再定義 Christopher symbol,
; 再定義 Christopher symbol,  , metric 的一階導數;再定義 curvature, 基本是 metric 的二階導數。
, metric 的一階導數;再定義 curvature, 基本是 metric 的二階導數。我們用 Landau 方法消除 
以下這步是關鍵,也是從 

也就是說: 
$latex \begin{aligned}
d s^{2} = 2(E-V) \sum_{j=1}^{n} \sum_{k=1}^{n} a_{j k} d q_{j} d q_{k} &=\sum_{j=1}^{n} \sum_{k=1}^{n} g_{j k} d q_{j} d q_{k}
\end{aligned} $
由此得到 metric (度規), 
完整的 Geodesic equation 如下。
Lengendre transform between Maupertuis and Least Action Principle
的 arc 如下,定義了 metric
E 是一個常數,E-V 就是動能。
How to derive a parabola from above?
 ) [@biesiadaEpicyclicOrbital2003]
) [@biesiadaEpicyclicOrbital2003]
比較一下,相對論的 (3D) Schwarzschild metric 如下。
在極限 (
完整的 geodesic equation:
In this case the geodesic deviation equation (for an orthogonal Jacobi field ξ of geodesic deviation 


因為 


$latex \forall \quad E>-\frac{GM}{r} \quad\left\{\begin{array}{llll}
E<0 & \Rightarrow & K_{G}>0 & ; & \text { ellipse } \\
E=0 & \Rightarrow & K_{G}=0 & ; & \text { parabola } \\
E>0 & \Rightarrow & K_{G}<0 \quad ; & & \text { hyperbola }
\end{array}\right. $
考慮圓形軌道半徑 

偶然看到 [@suUnderstandRiemann2016] 也有一樣的想法,以及類似的文章!摘錄做為參考。另外科學空間有很多文章值得一看 (ML, NLP, etc.)。和我的興趣非常相近。
以下是重點:
我們看具體的 2D 例子。BTW, 必須是 2D 或以上。 1D 的幾何只有直線。這裡用 general 2D 系統(假設 M=1),並且位能只是位置函數。
這個變分帶入 Euler-Lagrange, 可以得到牛頓運動方程式
由於是保守系統,那麼滿足能量守恆
代入第一式
再來他的推導顯然不分
也就是 Riemannian geometry metric is (E-V(x,y))
結論:
以上結果可以一般化,即如下作用量的保守系統
的能量為E的運動曲線的形狀(相軌線),等價於黎曼度量
下的測地線,其推導過程是類似的。這樣我們就實現了將力學的問題幾何化,或者說將二次型的變分問題幾何化了。可能讓人意外的是,以上結果在1837年就由雅可比完成了。
上面結果告訴我們,廣義相對論不再是黎曼幾何在物理中的代名詞,即便沒有廣義相對論,物理中也有黎曼幾何。將力學幾何化,有助於我們將力學、場論等與幾何聯繫起來。黎曼幾何其實就是一套幾何的研究框架,只要能夠對應地轉換,就可以直接應用黎曼幾何的很多結論,並且可能導出更豐富、更全面的內容。
Maupertuis advantage
Problem
x' = x – ut => dx' = dx – u
y' = y => dy' = dy
dx'2 + dy'2 = dx2 + dy2 – 2u dx + u2
[dx' dy' 1] = [1 0 -u; 0 1 0][dx dy 1]
TBD
我後來發現 Gray 有一篇非常好的文章 [@grayPrincipleLeast2009] 說明並解釋 Hamilton 最小作用原理,和 Maupertuis 最小作用原理!
現今最常使用的是 Hamilton 原理。 Hamilton action 


有無數條運動軌跡滿足給定 

where the constraint of fixed travel time 

第二個最小作用原理是 Maupertuis action 
where the first (time-independent) form is the general definition, with 



Maupertuis 原理描述所有軌跡 (time-independent)with fixed end positions 
注意 Maupertuis 原理
Solution of the variational problem posed by Hamilton's principle yields the true trajectories 
Solution of Maupertuis' variational equation using the time-dependent (second) form of
In one dimension, for simplicity assume 

In all cases the solutions for the true trajectories and orbits can be obtained directly from the Hamilton and Maupertuis variational principles or from the solution of the corresponding Euler-Lagrange differential equations which are equivalent to the variational principles.
Hamilton's principle is applicable to both conservative systems and nonconservative systems where the Lagrangian 

An appealing feature of the action principles is its brevity and elegance in expressing the laws of motion. They are valid for any choice of coordinates (i.e., they are covariant), and readily yield conservation laws from symmetries of the system. Action principles transcend classical particle and rigid body mechanics and extend naturally to other branches of physics such as continuum mechanics, relativistic mechanics, quantum mechanics, and field theory, and thus play a unifying role.
For conservative (time-invariant) systems the Hamilton and Maupertuis principles are related by a Legendre transformation. Recall first that the Lagrangian 

上式兩邊積分 with respect to t along an arbitrary virtual or trial trajectory between two points
where 

From the Legendre transformation between
We again restrict the discussion to time-invariant (conservative) systems. If we vary the trial trajectory 
Next one can show (Gray et al. 1996a) that the two sides separately vanish for variations around a true trajectory. The left side then gives 

where 




The right side gives 





這對於一般位能場成立,但對於例如電磁場就不成立,因為電磁力和速度相關。 ↩
Text classification 是 NLP 最基本的任務,應用廣泛。例如 sentiment analysis, spam filtering, news categorization, etc. 本文聚焦 fake news detection (classifying a news as REAL or FAKE) 任務。
此處我們 detect fake news using the state-of-the-art models, 也就是 BERT. 這個 tutorial 可以 extended to really any text classification task.
The Transformer is the basic building block of most current state-of-the-art architectures of NLP. Its primary advantage is its multi-head attention mechanisms which allow for an increase in performance and significantly more parallelization than previous competing models such as recurrent neural networks.
In this tutorial, we will use pre-trained BERT, one of the most popular transformer models, and fine-tune it on fake news detection. [@chengBERTText2020]
我們用 Kaggle "REAL and FAKE news dataset" (https://www.kaggle.com/nopdev/real-and-fake-news-dataset).
Dataset shape 7796×4, 1st column ID, 2nd column Title, 3rd column Text, 4th column Label. or 6335×4?

The raw data 如下:[@chengLSTMText2020]

The dataset contains an arbitrary index, title, text, and the corresponding label.
import pandas as pd
from sklearn.model_selection import train_test_split
raw_data_path = './Data/news.csv'
destination_folder = './Data'
train_test_ratio = 0.10
train_valid_ratio = 0.80
first_n_words = 200
def trim_string(x):
x = x.split(maxsplit=first_n_words)
x = ' '.join(x[:first_n_words])
return x
For preprocessing, 使用 Pandas and Sklearn 分為 train/valid/test csv files.
我們使用 trim_string function which will be used to cut each sentence to the first first_n_words words (e.g. 200). Trimming the samples in a dataset is not necessary but it enables faster training for heavier models and is normally enough to predict the outcome.
# Read raw data
df_raw = pd.read_csv(raw_data_path)
# Prepare columns
df_raw['label'] = (df_raw['label'] == 'FAKE').astype('int')
df_raw['titletext'] = df_raw['title'] + ". " + df_raw['text']
df_raw = df_raw.reindex(columns=['label', 'title', 'text', 'titletext'])
# Drop rows with empty text
df_raw.drop( df_raw[df_raw.text.str.len() < 5].index, inplace=True)
# Trim text and titletext to first_n_words
df_raw['text'] = df_raw['text'].apply(trim_string)
df_raw['titletext'] = df_raw['titletext'].apply(trim_string)
# Split according to label
df_real = df_raw[df_raw['label'] == 0]
df_fake = df_raw[df_raw['label'] == 1]
# Train-test split
df_real_full_train, df_real_test = train_test_split(df_real, train_size = train_test_ratio, random_state = 1)
df_fake_full_train, df_fake_test = train_test_split(df_fake, train_size = train_test_ratio, random_state = 1)
# Train-valid split
df_real_train, df_real_valid = train_test_split(df_real_full_train, train_size = train_valid_ratio, random_state = 1)
df_fake_train, df_fake_valid = train_test_split(df_fake_full_train, train_size = train_valid_ratio, random_state = 1)
# Concatenate splits of different labels
df_train = pd.concat([df_real_train, df_fake_train], ignore_index=True, sort=False)
df_valid = pd.concat([df_real_valid, df_fake_valid], ignore_index=True, sort=False)
df_test = pd.concat([df_real_test, df_fake_test], ignore_index=True, sort=False)
# Write preprocessed data
df_train.to_csv(destination_folder + '/train.csv', index=False)
df_valid.to_csv(destination_folder + '/valid.csv', index=False)
df_test.to_csv(destination_folder + '/test.csv', index=False)
We import Pytorch for model construction, torchText for loading data, matplotlib for plotting, and sklearn for evaluation.
參考 [@chengBERTText2020]
tokenizer是一個將純文本轉換為編碼的過程,該過程不涉及將詞轉換成為詞向量,僅僅是對純文本進行分詞,並且添加[MASK]、[SEP]、[CLS] 等等標記,然後將這些詞轉換為字典索引。
如上例所示,[CLS] 一般會被放在輸入序列的最前面,而 zero padding 在之前的 Transformer 文章裡已經有非常詳細的介紹。[MASK] token 一般在 fine-tuning 或是 feature extraction 時不會用到,這邊只是為了展示預訓練階段的克漏字任務才使用的。
For the tokenizer, we use the “bert-base-uncased” version of BertTokenizer.
另外我們用 TorchText, we first create the Text Field and the Label Field. The Text Field will be used for containing the news articles and the Label is the true target. We limit each article to the first 128 tokens for BERT input. 利用 Field 中的 encoder.
最後 we create a TabularDataset from our dataset csv files using the two Fields to produce the train, validation, and test sets. Then we create Iterators to prepare them in batches.
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Model parameter
MAX_SEQ_LEN = 128
PAD_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)
UNK_INDEX = tokenizer.convert_tokens_to_ids(tokenizer.unk_token)
# Fields
label_field = Field(sequential=False, use_vocab=False, batch_first=True, dtype=torch.float)
text_field = Field(use_vocab=False, tokenize=tokenizer.encode, lower=False, include_lengths=False, batch_first=True,
fix_length=MAX_SEQ_LEN, pad_token=PAD_INDEX, unk_token=UNK_INDEX)
fields = [('label', label_field), ('title', text_field), ('text', text_field), ('titletext', text_field)]
# TabularDataset
train, valid, test = TabularDataset.splits(path=source_folder, train='train.csv', validation='valid.csv',
test='test.csv', format='CSV', fields=fields, skip_header=True)
# Iterators
train_iter = BucketIterator(train, batch_size=16, sort_key=lambda x: len(x.text),
device=device, train=True, sort=True, sort_within_batch=True)
valid_iter = BucketIterator(valid, batch_size=16, sort_key=lambda x: len(x.text),
device=device, train=True, sort=True, sort_within_batch=True)
test_iter = Iterator(test, batch_size=16, device=device, train=False, shuffle=False, sort=False)
class BERT(nn.Module):
def __init__(self):
super(BERT, self).__init__()
options_name = "bert-base-uncased"
self.encoder = BertForSequenceClassification.from_pretrained(options_name)
def forward(self, text, label):
loss, text_fea = self.encoder(text, labels=label)[:2]
return loss, text_fea
We are using the “bert-base-uncased” version of BERT, which is the smaller model trained on lower-cased English text (with 12-layer, 768-hidden, 12-heads, 110M parameters).
# Save and Load Functions
def save_checkpoint(save_path, model, valid_loss):
if save_path == None:
return
state_dict = {'model_state_dict': model.state_dict(),
'valid_loss': valid_loss}
torch.save(state_dict, save_path)
print(f'Model saved to ==> {save_path}')
def load_checkpoint(load_path, model):
if load_path==None:
return
state_dict = torch.load(load_path, map_location=device)
print(f'Model loaded from <== {load_path}')
model.load_state_dict(state_dict['model_state_dict'])
return state_dict['valid_loss']
def save_metrics(save_path, train_loss_list, valid_loss_list, global_steps_list):
if save_path == None:
return
state_dict = {'train_loss_list': train_loss_list,
'valid_loss_list': valid_loss_list,
'global_steps_list': global_steps_list}
torch.save(state_dict, save_path)
print(f'Model saved to ==> {save_path}')
def load_metrics(load_path):
if load_path==None:
return
state_dict = torch.load(load_path, map_location=device)
print(f'Model loaded from <== {load_path}')
return state_dict['train_loss_list'], state_dict['valid_loss_list'], state_dict['global_steps_list']
We use Adam optimizer and a suitable learning rate to tune BERT for 5 epochs.
We use BinaryCrossEntropy as the loss function since fake news detection is a two-class problem. Make sure the output is passed through Sigmoid before calculating the loss between the target and itself.

# Evaluation Function
def evaluate(model, test_loader):
y_pred = []
y_true = []
model.eval()
with torch.no_grad():
for (labels, title, text, titletext), _ in test_loader:
labels = labels.type(torch.LongTensor)
labels = labels.to(device)
titletext = titletext.type(torch.LongTensor)
titletext = titletext.to(device)
output = model(titletext, labels)
_, output = output
y_pred.extend(torch.argmax(output, 1).tolist())
y_true.extend(labels.tolist())
print('Classification Report:')
print(classification_report(y_true, y_pred, labels=[1,0], digits=4))
cm = confusion_matrix(y_true, y_pred, labels=[1,0])
ax= plt.subplot()
sns.heatmap(cm, annot=True, ax = ax, cmap='Blues', fmt="d")
ax.set_title('Confusion Matrix')
ax.set_xlabel('Predicted Labels')
ax.set_ylabel('True Labels')
ax.xaxis.set_ticklabels(['FAKE', 'REAL'])
ax.yaxis.set_ticklabels(['FAKE', 'REAL'])
best_model = BERT().to(device)
load_checkpoint(destination_folder + '/model.pt', best_model)
evaluate(best_model, test_iter)

After evaluating our model, we find that our model achieves an impressive accuracy of 96.99%! 比起同樣的 LSTM model 只有 77.5%!
Cheng, Raymond. 2020a. “BERT Text Classification Using Pytorch.” Medium.
July 22, 2020.
https://towardsdatascience.com/bert-text-classification-using-pytorch-723dfb8b6b5b.
———. 2020b. “LSTM Text Classification Using Pytorch.” Medium. July 22,
2020.
https://towardsdatascience.com/lstm-text-classification-using-pytorch-2c6c657f8fc0.
中文自然語言處理的其中一個重要環節就是斷詞的處理。英文字詞基本相同,斷詞非常容易,直接用 space 就可以斷字或斷詞。中文斷詞在先天上就比較難處理,比如電腦要怎麼知道「全台大停電」要斷詞成「全台 / 大 / 停電」或是 「全/台大 / 停電」呢?如果是英文「Power outage all over Taiwan」,就可以直接用空白斷成「Power / outage / all / over / Taiwan」,可見中文斷詞是一個大問題。因為斷詞有歧義的可能如上,所以後面用分詞來替代斷詞。英文也會有姓名,專有名詞,復合名詞需要分詞,不過比起中文分詞還是相對容易。
中文分詞根據實現原理和特點,主要分為以下2個類別:
也稱字符串匹配分詞算法。該算法是按照一定的策略將待匹配的字符串和一個已建立好的「充分大的」詞典中的詞進行匹配,若找到某個詞條,則說明匹配成功,識別了該詞。常見的基於詞典的分詞算法分為以下幾種:正向最大匹配法、逆向最大匹配法和雙向匹配分詞法等。
基於詞典的分詞算法是應用最廣泛、分詞速度最快的。很長一段時間內研究者都在對基於字符串匹配方法進行優化,比如最大長度設定、字符串存儲和查找方式以及對於詞表的組織結構,比如採用TRIE索引樹、Hash 索引等。
這類目前常用的是算法是HMM、CRF (Conditional Random Field)、SVM、深度學習等算法,比如 Stanford、Hanlp 分詞工具是基於 CRF 算法。以 CRF 為例,基本思路是對漢字進行標注訓練,不僅考慮了詞語出現的頻率,還考慮上下文,具備較好的學習能力,因此其對歧義詞和未登錄詞的識別都具有良好的效果。
例如 JIEBA 中文分詞所使用的演算法是基於 TRIE TREE 結構去生成句子中中文字所有可能成詞的情況,然後使用動態規劃(DYNAMIC PROGRAMMING)算法來找出最大機率的路徑,這個路徑就是基於詞頻的最大分詞結果。對於辨識新詞(字典詞庫中不存在的詞)則使用了 HMM 模型及 VITERBI 算法來辨識出來。基本上這樣就可以完成具有分詞功能的程式了。
目前中文分詞難點主要有三個:
Bert並沒有使用分詞工具,是採用token級別進行輸入的,簡單來說就是字級別,具體參見tokenization.py 這個文件。[@leeBERTShiRuHeFenCiDe2019]
tokenization.py 就是預處理進行分詞的程序,主要有兩個分詞器:BasicTokenizer和WordpieceTokenizer,另外一個FullTokenizer是這兩個的結合:先進行BasicTokenizer得到一個分得比較粗的 token 列表,然後再對每個 token 進行一次 WordpieceTokenizer,得到最終的分詞結果。
BERT 源碼中 tokenization.py 就是預處理進行分詞的程序,主要有兩個分詞器:BasicTokenizer 和 WordpieceTokenizer,另外一個 FullTokenizer 是這兩個的結合:先進行 BasicTokenizer 得到一個分得比較粗的 token 列表,然後再對每個 token 進行一次 WordpieceTokenizer,得到最終的分詞結果。
為了能直觀看到每一步處理效果,我會用下面這個貫穿始終的例子來說明,該句修改自 Keras 的維基百科介紹:
example = "Keras是ONEIROS(Open-ended Neuro-Electronic Intelligent Robot Operating System,開放式神經電子智能機器人操作系統)項目研究工作的部分產物[3],主要作者和維護者是Google工程師François Chollet。\r\n"
BasicTokenizer(以下簡稱 BT)是一個初步的分詞器。對於一個待分詞字符串,流程大致就是轉成 unicode -> 去除各種奇怪字符 -> 處理中文 -> 空格分詞 -> 去除多餘字符和標點分詞 -> 再次空格分詞,結束。
大致流程就是這樣,還有很多細節,下面我依次說下。
轉成 unicode 這步對應於 convert_to_unicode(text) 函數,很好理解,就是將輸入轉成 unicode 字符串,如果你用的 Python 3 而且輸入是 str 類型,那麼這點無需擔心,輸入和輸出一樣;如果是 Python 3 而且輸入類型是 bytes,那麼該函數會使用 text.decode("utf-8", "ignore") 來轉成 unicode 類型。如果你用的是 Python 2,那麼請看 Sunsetting Python 2 support 和 Python 2.7 Countdown ,Just drop it。
經過這步後,example 和原來相同:
>>> example = convert_to_unicode(example)
>>> example
'Keras是ONEIROS(Open-ended Neuro-Electronic Intelligent Robot Operating System,開放式神經電子智能機器人操作系統)項目研究工作的部分產物[3],主要作者和維護者是Google工程師François Chollet。\r\n'
去除各種奇怪字符對應於 BT 類的 _clean_text(text) 方法,通過 Unicode 碼位(Unicode code point,以下碼位均指 Unicode 碼位)來去除各種不合法字符和多餘空格,包括:
經過這步後,example 中的 \r\n 被替換成兩個空格:
>>> example = _clean_text(example)
>>> example
'Keras是ONEIROS(Open-ended Neuro-Electronic Intelligent Robot Operating System,開放式神經電子智能機器人操作系統)項目研究工作的部分產物[3],主要作者和維護者是Google工程師François Chollet。 '
處理中文對應於 BT 類的 _tokenize_chinese_chars(text) 方法。對於 text 中的字符,首先判斷其是不是「中文字符」(關於中文字符的說明見下方引用塊說明),是的話在其前後加上一個空格,否則原樣輸出。那麼有一個問題,如何判斷一個字符是不是「中文」呢?
_is_chinese_char(cp) 方法,cp 就是剛才說的碼位,通過碼位來判斷,總共有 81520 個字,詳細的碼位範圍如下(都是閉區間):
[0x4E00, 0x9FFF]:十進制 [19968, 40959]
[0x3400, 0x4DBF]:十進制 [13312, 19903]
[0x20000, 0x2A6DF]:十進制 [131072, 173791]
[0x2A700, 0x2B73F]:十進制 [173824, 177983]
[0x2B740, 0x2B81F]:十進制 [177984, 178207]
[0x2B820, 0x2CEAF]:十進制 [178208, 183983]
[0xF900, 0xFAFF]:十進制 [63744, 64255]
[0x2F800, 0x2FA1F]:十進制 [194560, 195103]
經過這步後,中文被按字分開,用空格分隔,但英文數字等仍然保持原狀:
>>> example = _tokenize_chinese_chars(example)
>>> example
'Keras 是 ONEIROS(Open-ended Neuro-Electronic Intelligent Robot Operating System, 开 放 式 神 经 电 子 智 能 机 器 人 操 作 系 统 ) 项 目 研 究 工 作 的 部 分 产 物 [3], 主 要 作 者 和 维 护 者 是 Google 工 程 师 François Chollet。 '
空格分詞對應於 whitespace_tokenize(text) 函數。首先對 text 進行 strip() 操作,去掉兩邊多餘空白字符,然後如果剩下的是一個空字符串,則直接返回空列表,否則進行 split() 操作,得到最初的分詞結果 orig_tokens。
經過這步後,example 變成一個列表:
>>> example = whitespace_tokenize(example)
>>> example
['Keras', '是', 'ONEIROS(Open-ended', 'Neuro-Electronic', 'Intelligent', 'Robot', 'Operating', 'System,', '開', '放', '式', '神', '經', '電', '子', '智', '能', '機', '器', '人', '操', '作', '系', '統', ')', '項', '目', '研', '究', '工', '作', '的', '部', '分', '產', '物', '[3],', '主', '要', '作', '者', '和', '維', '護', '者', '是', 'Google', '工', '程', '師', 'François', 'Chollet。']
接下來是針對 orig_tokens 的分詞結果進一步處理,代碼如下:
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
邏輯不複雜,先轉成小寫。這裡主要說下 _run_strip_accents 和 _run_split_on_punc。
_run_strip_accents(text) 方法用於去除 accents,即變音符號,那麼什麼是變音符號呢?像 Keras 作者 François Chollet 名字中些許奇怪的字符 ç、簡歷的英文 résumé 中的 é 和中文拼音聲調 á 等,這些都是變音符號 accents,維基百科中描述如下:
附加符號或稱變音符號(diacritic、diacritical mark、diacritical
point、diacritical sign),是指添加在字母上面的符號,以更改字母的
發音或者以區分拼寫相似詞語。例如漢語拼音字母"ü"上面的兩個小點,
或"á"、"à"字母上面的標調符。
_run_strip_accents(text) 方法就是要把這些 accents 去掉,例如 François Chollet 變成 Francois Chollet,résumé 變成 resume,á 變成 a。
_run_split_on_punc(text) 是標點分詞,按照標點符號分詞。
經過這步後,原先沒有被分開的字詞標點(例如 ONEIROS(Open-ended)、沒有去掉的變音符號(例如 ç)都被相應處理:
>>> example
['keras', '是', 'oneiros', '(', 'open', '-', 'ended', 'neuro', '-', 'electronic', 'intelligent', 'robot', 'operating', 'system', ',', '開', '放', '式', '神', '經', '電', '子', '智', '能', '機', '器', '人', '操', '作', '系', '統', ')', '項', '目', '研', '究', '工', '作', '的', '部', '分', '產', '物', '[', '3', ']', ',', '主', '要', '作', '者', '和', '維', '護', '者', '是', 'google', '工', '程', '師', 'francois', 'chollet', '。']
這就是 BT 最終的輸出了。
WordpieceTokenizer(以下簡稱 WPT)是在 BT 結果的基礎上進行再一次切分,得到子詞(subword,以 ## 開頭),詞彙表就是在此時引入的。該類只有兩個方法:一個初始化方法 init(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200),一個分詞方法 tokenize(self, text)。
對於中文來說,使不使用 WPT 都一樣,因為中文經過 BasicTokenizer 後已經變成一個字一個字了,沒法再「子」了。
init(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):vocab 就是詞彙表,collections.OrderedDict() 類型,由 load_vocab(vocab_file) 讀入,key 為詞彙,value 為對應索引,順序依照 vocab_file 中的順序。有一點需要注意的是,詞彙表中已包含所有可能的子詞。unk_token 為未登錄詞的標記,默認為 [UNK]。max_input_chars_per_word 為單個詞的最大長度,如果一個詞的長度超過這個最大長度,那麼直接將其設為 unk_token。
tokenize(self, text):該方法就是主要的分詞方法了,大致分詞思路是按照從左到右的順序,將一個詞拆分成多個子詞,每個子詞盡可能長。按照源碼中的說法,該方法稱之為 greedy longest-match-first algorithm,貪婪最長優先匹配算法。
開始時首先將 text 轉成 unicode,並進行空格分詞,然後依次遍歷每個詞。為了能夠清楚直觀地理解遍歷流程,我特地製作了一個 GIF 來解釋,以 unaffable 為例:
將 BT 的結果輸入給 WPT,那麼 example 的最終分詞結果就是
['keras', '是', 'one', '##iros', '(', 'open', '-', 'ended', 'neu', '##ro', '-', 'electronic', 'intelligent', 'robot', 'operating', 'system', ',', '開', '放', '式', '神', '經', '電', '子', '智', '能', '機', '器', '人', '操', '作', '系', '統', ')', '項', '目', '研', '究', '工', '作', '的', '部', '分', '產', '物', '[', '3', ']', ',', '主', '要', '作', '者', '和', '維', '護', '者', '是', 'google', '工', '程', '師', 'franco', '##is', 'cho', '##llet', '。']
至此,BERT 分詞部分結束。
Lee, Alan. 2019. “BERT 是如何分词的.” October 16, 2019.
https://alanlee.fun/2019/10/16/bert-tokenizer/.
下圖整理簡單的 Neural history of NLP from [@ruderReviewRecent2018], [@suSeq2seqPay2018], and [@suSeq2seqPay2018a]

近年注意力模型 (Attention Model) 是深度學習領域最受矚目的新星,用來處理與序列相關的資料,特別是2017年 Google 提出 self attention 後,模型成效、複雜度又取得了更大的進展。然而,從 Attention model 讀到 self attention 時,遇到不少障礙,其中很大部分是後者在論文提出的概念,鮮少有文章解釋如何和前者做關聯。希望藉由這系列文,解釋在機器翻譯的領域中,是如何從Seq2seq演進至Attention model 再至 self attention,使讀者在理解Attention 機制不再這麼困難。Attention 的演進史如下圖,對應上圖的 Attention stage.

前文提到 Seq2Seq 包含 encoder 和 decoder 兩個 RNN 所構成。它的運作原理其實與人類的思維很相似,當我們看到一段話時,會先將這句話理解吸收,再根據我們理解的內容說出回覆,Sequence to Sequence 就是在模擬這個過程。

Encoder 就是負責將輸入序列消化、吸收成一個向量,我們通常把這個向量稱為 context vector,顧名思義,這個向量會囊括原序列的重要訊息。而 Decoder 則是根據 context vector 來生成文字。
甚至,我們能把眼光放得更遠些,Encoder 與 Decoder 不一定都只有 RNN,可以讓 CNN 與 RNN 一起當 Encoder,負責將影像編碼成向量,而 Decoder 根據這個向量來生成描述,這樣就能讓機器描述圖片中發生了什麼:
但是 Seq2Seq 模型其實有一個很大的缺陷,那就是我們把一個不限長的輸入,給編碼成一個固定長度的向量,換句話說,隨著我們的輸入越來越長,context/thought vector 的訊息損失就會越大。這方法顯然不太科學,就連我們在聽課時,都不免聽了後面就忘了前面,又怎麼能要求一個向量記住所有資訊呢?
2015 Luong et al. of Stanford 的文章在 Seq2Seq model 加上 attention model 解決長句子 context vector 訊息損失的問題。[@luongEffectiveApproaches2015] and [@alammarVisualizingNeural2018]
這種新的架構替輸入句的每個文字都創造一個context vector,而非僅僅替輸入句創造一個從最終的hidden state 得來的context vector. 舉例來說,如果一個輸入句有N個文字,就會產生N個context vector,好處是,每個context vector能夠被更有效的解碼。

什麼是 attention? Attention 的直覺想法是當模型輸出某件事時,只會專注於與這件事相關的輸入,這很像在學習一種配對關係。目的在建立 decoder output (例如 translated word, query and answer) 和 specific input word(s) (or encoder hidden state) 的相關性。
在 Attention model 中,Encoder 和 Seq2Seq 概念一樣,一樣是從輸入句 <



Context vector

Attention score α 是 attention model中提出一個很重要的概念,可以用來衡量輸入句中的每個文字對目標句中的每個文字所帶來重要性的程度。由下面公式可知,attention score 藉由 score 


再來是 score: 
換言之, 


[@luongEffectiveApproaches2015] 發表之後,接續的論文提出了global/local attention 和 soft/hard attention 的概念,而 score 



有了score

我們用 attention vector/matrix 取代 context vector, 避免 context vector 的兩個缺點:(1) encoder information loss; => attention vector 解決這個問題。 (2) 我們不知道 context vector 到底學到什麼; => attention matrix 提供 visualization 結果。
回過來看 encoder, attention model 中的 encoder 用的是改良版 RNN:雙向 RNN(Bi-directional RNN) 如上上上圖,以往單向RNN的問題在於t時刻時,只能透過之前的訊息進行預測,但事實上,模型有時候可能也需要利用未來時刻的訊息進行預測,其運作模式為,一個hidden layer用來由左到右,另一個由右到左,透過雙向RNN,我們可以對詞語進行更好的預測。
舉例來說,”我喜歡蘋果,因為它很好吃”?和”我喜歡蘋果,因為他比安卓穩定”這兩個句子當中,如果只看”我喜歡蘋果”,你可能不知道蘋果指的是水果還是手機,但如果可以根據後面那句得到訊息,答案就很顯而易見,這就是雙向RNN運作的方式。
Attention model 雖然解決了輸入句僅有一個 context vector 的缺點,但依舊存在不少問題。
什麼是 attention? Attention 的直覺想法是當模型輸出某件事時,只會專注於與這件事相關的輸入,這很像在學習一種配對關係。目的在建立 decoder output (例如 translated word, query and answer) 和 specific input word(s) (or encoder hidden state) 的相關性。
例如輸入是法文的 "Je suis etudiant", 輸出是英文的 “I am a student". 我們期待如下表 attention table, 越深色代表相關性越高。可以看到 "Je -> I", "suis -> am a", "etudiant -> a student". Attention 不僅可以幫助 explain/validate/debug neural network model (可視化 or explainable AI). 另外藉著移除不重要的 information, 有機會 "understand" the content. 這在 attention 用於圖像更明顯。例如 video caption, 對應 NLP article summary 應用。
具體做法是把 input sentence encoder 所有的 hidden states 而非只有 final state context vector (雖然這個 final state 包含所有之前 hidden state) 饋入 decoder. [@fuyuAttentionMechanism2020] 下表每一個 output word 基本對應 encoder hidden states weighted sum. Hidden state 佔比重越大,表示相關性 (attention) 越高。這種 attention 稱為 encoder-decoder attention.

在2017年,Google提出了一種叫做”The transformer”的模型,透過幾個新的觀念:(1) self attention; (2)multi-head attention; 擴展 attention 的概念去解決上述缺點; 並且 (3) 完全捨棄了RNN、CNN的架構。
除了 encoder-decoder attention 之外,還有一種更基本的 attention: self-attention. Self-attention 是捕捉同一句子或文章中任一 word (or token) 對其他 words (tokens) 的相關性。這聽起來像是 word embedding: 從幾個上下文 words (or token) 


所以到底 self-attention encoder 和 word embedding 有什麼不同?可以參考下表:
| Self-attention encoder | Word embedding | |
|---|---|---|
| Deeper | stacking encoders, transformer: 6 | 1 linear + softmax |
| Wider, Reception Field | entire sentence or article, transformer: 128 | a few (<10) words |
| Multi-Head Attention | Yes, 1 word has multiple attentions. Contextual word embedding | 1 word 1 attention, 1 fixed vector |
Word embedding 的精神是 “word is defined by its neighbor!" CBOW 的 word embedding training 只用 single word (or token) 為單位,把 one-hot encoding sparse vector (~20,000 維) 轉換成 dense vector (~512 維 or less).
Contextual word embedding 的精神是 “word is defined by its context!" 更 specific “word is defined by its attended words!"
這個相關性不單是 local 在這個句子。而是用 contextual word embedding 來表示。
舉一些例子:
2017 來自 Google 的這篇文章:"Attention Is All You Need" 建立一個新的里程碑。 [@vaswaniAttentionAll2017] 這篇文章要解決的是翻譯問題,比如從中文翻譯成英文。這篇文章完全放棄了以往經常採用的 RNN 和 CNN,而提出了一種新的網絡結構,即Transformer,其中包括 encoder 和 decoder (來自 Sequence-to-Sequence model!)。
下圖左是 Transformer model consists of 1 encoder and 1 decoder. 下圖右是完整的 transformer consists of 6 encoder + 6 decoder stacks.

再把 transformer 放大。下圖左半部是 encoder, 下圖右半部是 decoder. Decoder 的 output (shift right) 再饋入 decoder 的 input 產生下一個 output. 基本框架和 sequence-to-sequence 一樣。不過相似之處到此為止。接下來是 transformer 的獨特之處。 [@alammarIllustratedTransformer2018] 對 transformer 介紹非常仔細。

Why Query, Key, Value?
簡單來說,因為沒有 RNN 的 encoder and decoder hidden vectors. 我們需要一個新的機制計算 attention vector/matrix.
在NLP的領域中,Key, Value通常就是指向同一個文字隱向量(word embedding vector)。
進入”The transformer”前,我們重新複習attention model,attention model是從輸入句<


如果用另一種說法重新詮釋:
輸入句中的每個文字是由一系列成對的 <地址Key, 元素Value> 所構成,而目標中的每個文字是Query,那麼就可以用Key, Value, Query去重新解釋如何計算context vector,透過計算Query和各個Key的相似性,得到每個Key對應Value的權重係數,權重係數代表訊息的重要性,亦即attention score;Value則是對應的訊息,再對Value進行加權求和,得到最終的Attention/context vector。
筆者認為這概念非常創新,特別是從 attention model 到 ”The transformer” 間,鮮少有論文解釋這種想法是如何連結的,間接導致 ”attention is all you need” 這篇論文難以入門,有興趣可以參考key、value的起源論文 Key-Value Memory Networks for Directly Reading Documents。

有了 Key, Value, Query 的概念,我們可以將 attention model 中的 Decoder 公式重新改寫。
 ,上文有提到3種計算權重的方式,而我們選擇用內積。
,上文有提到3種計算權重的方式,而我們選擇用內積。 ,便可以透過softmax算出
,便可以透過softmax算出 ,接著就可以透過attention score
,接著就可以透過attention score  乘上
乘上 的序列和加總所得 = Attention(Query, Source),也就是context/attention vector。
的序列和加總所得 = Attention(Query, Source),也就是context/attention vector。
“The transformer”在計算attention的方式有三種,1. encoder self attention,存在於encoder間. 2. decoder self attention,存在於decoder間,3. encoder-decoder attention, 這種attention算法和過去的attention model相似。 其中 1 and 2 都是 Google paper 新的觀念。
三種 attention 對應的 query, key, value 如下。

通過這樣一系列的計算,可以看到,現在每個詞的輸出向量z都包含了其他詞的信息,每個詞都不再是孤立的了。而且每個位置中,詞與詞的相關程度,可以通過softmax輸出的權重進行分析。如下圖所示,這是某一次計算的權重,其中線條顏色的深淺反映了權重的大小,可以看到it中權重最大的兩個詞是The和animal,表示it跟這兩個詞關聯最大。這就是attention的含義,輸出跟哪個詞關聯比較強,就放比較多的注意力在上面。上面我們把每一步計算都拆開了看,實際計算的時候,可以通過矩陣來計算。

講完了attention,再來講Multi-Head。對於同一組輸入embedding,我們可以並行做若干組上面的操作,例如,我們可以進行8組這樣的運算,每一組都有WQ,WK,WV矩陣,並且不同組的矩陣也不相同。這樣最終會計算出8組輸出,我們把8組的輸出連接起來,並且乘以矩陣WO做一次線性變換得到輸出,WO也是隨機初始化,通過訓練得到。這樣的好處,一是多個組可以並行計算,二是不同的組可以捕捉不同的子空間的信息。我們用同樣的例子說明如下圖。

同樣都是做NLP任務,我們來和RNN做個對比。
下圖是最基本的RNN結構,計算公式:
當計算隱向量




但是Transformer這個結構就不存在這個問題,不管當前詞和其他詞的空間距離有多遠,包含其他詞的信息不取決於距離,而是取決於兩者的相關性,這是Transformer的第一個優勢。
第二個優勢在於,對於Transformer來說,在對當前詞進行計算的時候,不僅可以用到前面的詞,也可以用到後面的詞。而RNN只能用到前面的詞,這並不是個嚴重的問題,因為這可以通過雙向RNN來解決。
第三點,RNN是一個順序的結構,必須要一步一步地計算,只有計算出h1,才能計算h2,再計算h3,隱向量無法同時並行計算,導致RNN的計算效率不高,這是RNN的固有結構所造成的,之前有一些工作就是在研究如何對RNN的計算並行化。通過前文的介紹,可以看到Transformer不存在這個順序問題。
下圖 summarize 上述三點優勢。

通過這裡的比較,可以看到Transformer相對於RNN有巨大的優勢,因此 Google 認為 RNN之後會被Transformer取代: "Attention Is All You Need". 事實上 NLP 近年 (2017-) 的確被 attention-based model 如 transformer, BERT, GPT, etc. dominate.
但是 RNN 在 ASR (automatic speech recognition) 仍然廣泛使用。可能說話的循序的特性仍然和 RNN sequence model 相當吻合.
簡單來說:Transformer = Seq2Seq structure (encoder+decoder) + Attention (replace RNN with Attention). 其中 decoder 是 generative model, encoder 是 discriminative model (sort of). 我們可以分別用於不同應用。
首先 BERT = Transformer encoder
可以用 CBOW 的方式 training encoder,
另外雖然 RNN 逐漸被 Attention 取代,但仍然在 NLP 應用:
ELMo = Deep bi-directional LSTM model (encoder) [@petersDeepContextualized2018]
ELMo 雖然沒有 attention mechanism, 還是可以達到 contextual word embedding.
GPT = Transformer
GPT 則是 generative model, 包含 encoder + decoder, 其實就是很大的 transformer.
Why need pre-trained + fine-tuning?
How to do pre-trained and fine-tuing?
Refere to NTU Prof. Li's talk
Alammar, Jay. 2018a. “Visualizing A Neural Machine Translation Model
(Mechanics of Seq2seq Models with Attention).” May 9, 2018.
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/.
———. 2018b. “The Illustrated Transformer.” June 27, 2018.
https://jalammar.github.io/illustrated-transformer/.
Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. “Effective Approaches to Attention-Based Neural Machine Translation.” September 20, 2015. http://arxiv.org/abs/1508.04025.
Ruder, Sebastian. n.d. “A Review of the Recent History of Natural Language Processing.” Sebastian Ruder. Accessed January 27, 2021.
https://ruder.io/a-review-of-the-recent-history-of-nlp/.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. “Attention Is All You Need.” December 5, 2017. http://arxiv.org/abs/1706.03762.
Wang, Zhengyang, Yaochen Xie, and Shuiwang Ji. 2020. “Global Voxel Transformer Networks for Augmented Microscopy.” November 23, 2020.
http://arxiv.org/abs/2008.02340.
Yang, Justin. 2017. “從零開始的 Sequence to Sequence.” 雷德麥的藏書閣. September 28, 2017.
http://zake7749.github.io/2017/09/28/Sequence-to-Sequence-tutorial/index.html.
Zhang, Bei. 2019. “Transformer and BERT in NLP.” 知乎专栏. May 27, 2019. https://zhuanlan.zhihu.com/p/53099098.
sequenceDiagram
participant Alice
participant Bob
Alice->John: Hello John, how are you?
loop Healthcheck
John->John: Fight against hypochondria
end
Note right of John: Rational thoughts <br/>prevail...
John-->Alice: Great!
John->Bob: How about you?
Bob-->John: Jolly good!
graph LR
A[方形] -->B(圆角)
B --> C{条件a}
C -->|a=1| D[结果1]
C -->|a=2| E[结果2]
F[横向流程图]

多目標跟蹤 (MOT) 是監控重要的功能。雖然沒有 ImageNet 大量的 dataset, 但因為 MOT Challenge 的關係,MOT Challenge dataset 成為大家公認的 dataset 用於檢視 MOT 算法的效能。
MOT Challenge是多目標跟蹤領域最權威的國際測評平臺,由慕尼黑工業大學、阿德萊德大學、蘇黎世聯邦理工學院以及達姆施塔特工業大學聯合創辦。MOT Challenge 提供了非常準確的標註資料和全面的評估指標,用以評估跟蹤演算法、行人檢測器的效能。
這裡介紹這些 datasets.
數據集用的最多的是 MOTChallenge,專注於行人追蹤的: https://motchallenge.net/
針對 MOT16 數據集介紹一下,它與 MOT15 數據的部分標注信息可能存在差別,需要注意~
MOT16 數據集是在 2016 年提出來的用於衡量多目標跟蹤檢測和跟蹤方法標準的數據集,專門用於行人跟蹤。總共有 14 個視頻,訓練集和測試集各 7 個,這些視頻每個都不一樣,按照官網的說法,它們有些是固定攝像機進行拍攝的,有些是移動攝像機進行拍攝的,而且拍攝的角度各不一樣(低、中、高度進行拍攝),拍攝的條件不一樣,包括不同的天氣,白天或者夜晚等,還具有非常高的人群密度,總之,這個數據集非常具有挑戰性。
7 training sequence: {2, 4, 5, 9, 10, 11, 13} 如下表。

另一個 MOT16 7 training and test sequence summary.
MOT16 數據集使用的 baseline 檢測器是 DPM,這個檢測器在檢測 「人」 這個類別上具有較好的性能。我們看一些例子如下。這些視頻的主要信息如下:包括 FPS、分辨率、視頻時長、軌跡數、目標書、密度、靜止或者移動拍攝、低中高角度拍攝、拍攝的天氣條件等。

MOT16 數據的目錄結構如下所示:包含訓練集和測試集(各有 7 個視頻)
每個子文件夾(如 MOT16-01)代表一個視頻轉換後的數據集,包含幾個文件或者文件夾,其目錄結構與具體含義如下:
MOT16/
├── test
│ ├── MOT16-01
│ │ ├── det
│ │ │ └── det.txt
│ │ ├── img1
│ │ │ ├── 000001.jpg
│ │ │ ├── xxxxxx.jpg
│ │ │ └── 000450.jpg
│ │ └── seqinfo.ini
│ ├── MOT16-03
│ ├── MOT16-06
│ ├── MOT16-07
│ ├── MOT16-08
│ ├── MOT16-12
│ └── MOT16-14
│
└── train
├── MOT16-02
│ ├── det
│ │ └── det.txt
│ ├── gt
│ │ └── gt.txt
│ ├── img1
│ │ ├── 000001.jpg
│ │ ├── xxxxxx.jpg
│ │ └── 000600.jpg
│ └── seqinfo.ini
├── MOT16-04
├── MOT16-05
├── MOT16-09
├── MOT16-10
├── MOT16-11
└── MOT16-13
seqinfo.ini
文件內容如下,主要用於說明這個文件夾的一些信息,比如圖片所在文件夾 img1,幀率,視頻的長度,圖片的長和寬,圖片的後綴名。
det/det.txt
這個文件中存儲了圖片的檢測框的信息 (這裡用 MOT16-05 文件來說明,該文件下 img1 文件下有 837 張圖片,代表視頻的每一幀)
從左到右分別代表的意義是
第 1 個值:frame: 第幾幀圖片
第 2 個值:id: 這個檢測框分配的 id,(由於暫時未定,所以均為 – 1)
第 3-6 個值:bbox (四位): 分別是左上角坐標(top, left)和寬 (width) 高 (height)
第 7 個值:conf:這個 bbox 包含物體的置信度,可以看到並不是傳統意義的 0-1,分數越高代表置信度越高
第 8、9、10 個值:MOT3D (x,y,z): 是在 MOT3D 中使用到的內容,這裡關心的是 MOT2D,所以都設置為 -1
可以看出以上內容主要提供的和目標檢測的信息沒有區別,所以也在一定程度上可以用於檢測器的訓練。
img1 文件夾
這裡面是將視頻的每一幀抽取出來後的圖片,圖片格式是 jpg,按照視頻流的順序進行命名,如:xxxxxx.jpg
gt/gt.txt 文件(train 訓練集才有)
從左到右代表的含義是:
第 1 個值:frame: 第幾幀圖片
第 2 個值:ID: 也就是軌跡的 ID
第 3-6 個值:bbox: 分別是左上角坐標 (top, left) 和寬(width)高(height)
第 7 個值:是否忽略:0 代表忽略 (A value of 0 means that this particularinstance is ignored in the evaluation, while a value of1 is used to mark it as active.)
第 8 個值:classes: 目標的類別個數(這裡是駕駛場景包括 12 個類別),7 代表的是靜止的人。第 8 個類代表錯檢,9-11 代表被遮擋的類別,12 代表反射,如下圖中的第二列,可以看到店面的玻璃反射了路人的背景。

第 9 個值:代表目標運動時被其他目標包含、覆蓋、邊緣裁剪的情況。(The last number shows the visibility ratio of each bounding box. This can be due to occlusion by anotherstatic or moving object, or due to image border cropping.)
MOT17 baseline 提供了三種檢測結果: DPM, Faster-RCNN, and SDP,如果你分析基於不同檢測結果的結果,你會發現大多數 MOT tracker 在 Faster-RCNN 和 SDP 檢測上有著相似的性能。

KITTI 數據集的是針對自動駕駛的數據集,有汽車也有行人,在 MOT 的論文里用的很少。



























































![=\log \frac{p(x \mid z=i) \pi_{i}}{p(x \mid z=j) \pi_{j}}=\log \frac{\pi_{i} \frac{1}{\sqrt{\left|2 \pi \Sigma_{i}\right|}} \exp \left[-\frac{1}{2}\left(x-\mu_{i}\right)^{T} \Sigma_{i}^{-1}\left(x-\mu_{i}\right)\right]}{\pi_{j} \frac{1}{\sqrt{\left|2 \pi \Sigma_{j}\right|}} \exp \left[-\frac{1}{2}\left(x-\mu_{j}\right)^{T} \Sigma_{j}^{-1}\left(x-\mu_{j}\right)\right]}](https://s0.wp.com/latex.php?latex=%3D%5Clog+%5Cfrac%7Bp%28x+%5Cmid+z%3Di%29+%5Cpi_%7Bi%7D%7D%7Bp%28x+%5Cmid+z%3Dj%29+%5Cpi_%7Bj%7D%7D%3D%5Clog+%5Cfrac%7B%5Cpi_%7Bi%7D+%5Cfrac%7B1%7D%7B%5Csqrt%7B%5Cleft%7C2+%5Cpi+%5CSigma_%7Bi%7D%5Cright%7C%7D%7D+%5Cexp+%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x-%5Cmu_%7Bi%7D%5Cright%29%5E%7BT%7D+%5CSigma_%7Bi%7D%5E%7B-1%7D%5Cleft%28x-%5Cmu_%7Bi%7D%5Cright%29%5Cright%5D%7D%7B%5Cpi_%7Bj%7D+%5Cfrac%7B1%7D%7B%5Csqrt%7B%5Cleft%7C2+%5Cpi+%5CSigma_%7Bj%7D%5Cright%7C%7D%7D+%5Cexp+%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28x-%5Cmu_%7Bj%7D%5Cright%29%5E%7BT%7D+%5CSigma_%7Bj%7D%5E%7B-1%7D%5Cleft%28x-%5Cmu_%7Bj%7D%5Cright%29%5Cright%5D%7D+&bg=ffffff&fg=111111&s=0&c=20201002)














![\begin{aligned} & \frac{1}{\sqrt{2 \pi \sigma^{2}}} \exp \left(-\frac{(z-\mu)^{2}}{2 \sigma^{2}}\right) d z \\=& \frac{1}{\sqrt{2 \pi}} \exp \left[-\frac{1}{2}\left(\frac{z-\mu}{\sigma}\right)^{2}\right] d\left(\frac{z-\mu}{\sigma}\right) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%26+%5Cfrac%7B1%7D%7B%5Csqrt%7B2+%5Cpi+%5Csigma%5E%7B2%7D%7D%7D+%5Cexp+%5Cleft%28-%5Cfrac%7B%28z-%5Cmu%29%5E%7B2%7D%7D%7B2+%5Csigma%5E%7B2%7D%7D%5Cright%29+d+z+%5C%5C%3D%26+%5Cfrac%7B1%7D%7B%5Csqrt%7B2+%5Cpi%7D%7D+%5Cexp+%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28%5Cfrac%7Bz-%5Cmu%7D%7B%5Csigma%7D%5Cright%29%5E%7B2%7D%5Cright%5D+d%5Cleft%28%5Cfrac%7Bz-%5Cmu%7D%7B%5Csigma%7D%5Cright%29+%5Cend%7Baligned%7D+&bg=ffffff&fg=111111&s=0&c=20201002)

![\mathcal{S}\left[\mathbf{q}, t_{1}, t_{2}\right]=\int_{t_{1}}^{t_{2}} L(\mathbf{q}(t), \dot{\mathbf{q}}(t), t) d t](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D%5Cleft%5B%5Cmathbf%7Bq%7D%2C+t_%7B1%7D%2C+t_%7B2%7D%5Cright%5D%3D%5Cint_%7Bt_%7B1%7D%7D%5E%7Bt_%7B2%7D%7D+L%28%5Cmathbf%7Bq%7D%28t%29%2C+%5Cdot%7B%5Cmathbf%7Bq%7D%7D%28t%29%2C+t%29+d+t+&bg=ffffff&fg=111111&s=0&c=20201002)
![\mathcal{S}\left[\mathbf{q}, t_{1}, t_{2}\right]=\int_{t_{1}}^{t_{2}} L(\mathbf{q}(t), \dot{\mathbf{q}}(t), t) d t \quad\text{and}\quad \delta{\mathcal{S}} = 0](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D%5Cleft%5B%5Cmathbf%7Bq%7D%2C+t_%7B1%7D%2C+t_%7B2%7D%5Cright%5D%3D%5Cint_%7Bt_%7B1%7D%7D%5E%7Bt_%7B2%7D%7D+L%28%5Cmathbf%7Bq%7D%28t%29%2C+%5Cdot%7B%5Cmathbf%7Bq%7D%7D%28t%29%2C+t%29+d+t+%5Cquad%5Ctext%7Band%7D%5Cquad+%5Cdelta%7B%5Cmathcal%7BS%7D%7D+%3D+0+&bg=ffffff&fg=111111&s=0&c=20201002)










































![\mathcal{S}_{0} =\int \sum_{i} p_{i} d q_{i}=\int \sum_{i} a_{i k} d q_{i} d q_{k} / d t=\int \sqrt{\left[2(E-V) \sum a_{i k} d q_{i} d q_{k}\right]} = \int ds](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D_%7B0%7D+%3D%5Cint+%5Csum_%7Bi%7D+p_%7Bi%7D+d+q_%7Bi%7D%3D%5Cint+%5Csum_%7Bi%7D+a_%7Bi+k%7D+d+q_%7Bi%7D+d+q_%7Bk%7D+%2F+d+t%3D%5Cint+%5Csqrt%7B%5Cleft%5B2%28E-V%29+%5Csum+a_%7Bi+k%7D+d+q_%7Bi%7D+d+q_%7Bk%7D%5Cright%5D%7D+%3D+%5Cint+ds+&bg=ffffff&fg=111111&s=0&c=20201002)







![S=\int\left\{\frac{1}{2}\left[\left(\frac{d x}{d t}\right)^{2}+\left(\frac{d y}{d t}\right)^{2}\right]-U(x, y)\right\} d t](https://s0.wp.com/latex.php?latex=S%3D%5Cint%5Cleft%5C%7B%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B%5Cleft%28%5Cfrac%7Bd+x%7D%7Bd+t%7D%5Cright%29%5E%7B2%7D%2B%5Cleft%28%5Cfrac%7Bd+y%7D%7Bd+t%7D%5Cright%29%5E%7B2%7D%5Cright%5D-U%28x%2C+y%29%5Cright%5C%7D+d+t+&bg=ffffff&fg=111111&s=0&c=20201002)

![\frac{1}{2}\left[\left(\frac{d x}{d t}\right)^{2}+\left(\frac{d y}{d t}\right)^{2}\right]+U=E](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B%5Cleft%28%5Cfrac%7Bd+x%7D%7Bd+t%7D%5Cright%29%5E%7B2%7D%2B%5Cleft%28%5Cfrac%7Bd+y%7D%7Bd+t%7D%5Cright%29%5E%7B2%7D%5Cright%5D%2BU%3DE++&bg=ffffff&fg=111111&s=0&c=20201002)
![S=\int\left[\left(\frac{d x}{d t}\right)^{2}+\left(\frac{d y}{d t}\right)^{2}-E\right] d t](https://s0.wp.com/latex.php?latex=S%3D%5Cint%5Cleft%5B%5Cleft%28%5Cfrac%7Bd+x%7D%7Bd+t%7D%5Cright%29%5E%7B2%7D%2B%5Cleft%28%5Cfrac%7Bd+y%7D%7Bd+t%7D%5Cright%29%5E%7B2%7D-E%5Cright%5D+d+t++&bg=ffffff&fg=111111&s=0&c=20201002)

![S=\int\left[\frac{1}{2} g_{\mu \nu} \frac{d x^{\mu}}{d t} \frac{d x^{\nu}}{d t}-U(x)\right] d t](https://s0.wp.com/latex.php?latex=S%3D%5Cint%5Cleft%5B%5Cfrac%7B1%7D%7B2%7D+g_%7B%5Cmu+%5Cnu%7D+%5Cfrac%7Bd+x%5E%7B%5Cmu%7D%7D%7Bd+t%7D+%5Cfrac%7Bd+x%5E%7B%5Cnu%7D%7D%7Bd+t%7D-U%28x%29%5Cright%5D+d+t++&bg=ffffff&fg=111111&s=0&c=20201002)
![d s^{2}=[E-U(\boldsymbol{x})] g_{\mu \nu} d x^{\mu} d x^{\nu}](https://s0.wp.com/latex.php?latex=d+s%5E%7B2%7D%3D%5BE-U%28%5Cboldsymbol%7Bx%7D%29%5D+g_%7B%5Cmu+%5Cnu%7D+d+x%5E%7B%5Cmu%7D+d+x%5E%7B%5Cnu%7D++&bg=ffffff&fg=111111&s=0&c=20201002)











![h_{i}=f\left(\left[W \cdot x_{i}, U \cdot h_{i-1},\right]+b\right)](https://s0.wp.com/latex.php?latex=h_%7Bi%7D%3Df%5Cleft%28%5Cleft%5BW+%5Ccdot+x_%7Bi%7D%2C+U+%5Ccdot+h_%7Bi-1%7D%2C%5Cright%5D%2Bb%5Cright%29+&bg=ffffff&fg=111111&s=0&c=20201002)